WMT-2020ニュース翻訳タスクに参加して
清野 舜1,2 伊藤 拓海2,1 今野 颯人2,1 森下 睦3,2 鈴木 潤2,1(代表執筆)
1理研AIP 2東北大学 3NTTコミュニケーション科学基礎研究所
1. はじめに
このたびは,WMT-2020ニュース翻訳タスクに参加した「Team Tohoku-AIP-NTT(チームメンバーは本稿の著者全員)」が構築した機械翻訳システム,および,ニュース翻訳タスクにおける成績を高く評価していただき,第16回AAMT長尾賞に選出していただきましたこと,選考委員の方々をはじめ関係者の皆様に,この場をお借りして御礼申し上げます.
著者らの解釈では,オンラインの機械翻訳サービス開発を一般向け自動車開発とみなすと,WMTのコンペティション用の機械翻訳システム開発は,自動車競技F1のような事前に決められたレギュレーション下でどれだけ良いものを作れるか,という趣旨のシステム開発に相当すると考えています.その意味では,AAMT長尾賞の一番の趣旨である「機械翻訳システムの実用化の促進および実用化のための研究開発に貢献した個人あるいはグループの表彰」からはやや外れる部分もあると認識しておりますが,機械翻訳開発に関連する大きな成果と認定していただけたことを,著者一同非常に嬉しく思っています.
本稿では,機械翻訳におけるWMTの役割や,今回の成果の位置付けなどを説明させていただくとともに,WMT-2020参加システムの要点や,良好な成績を得られた理由を簡単に紹介したいと思います.1
2. WMTの概要
WMTとは,元々はWorkshop on Statistical Machine Translationの略称であり,2006年に統計翻訳 (Statistical Machine Translation) に特化したワークショップとして出発し,それ以来毎年開催されている.略称のWMTは,2006年の第一回目から現在まで変わっていないが,第11回目の2016年よりワークショップから国際会議に格上げされ,WMTはConference on Machine Translationの略称となった.つまり,WorkshopからConferenceに変更になったタイミングで「Statistical」が消去され,「統計翻訳に特化したワークショップ」から「機械翻訳全般の国際会議」へと変更された.これは,丁度,統計翻訳からニューラル翻訳へと時代が転換する時に合わせての名称変更となった2. 現在,機械翻訳を専門とする国際会議として広く知られている.
WMTの大きな特徴の一つとして,毎年機械翻訳に関連するコンペティション(通称Shared task)が開催されることが挙げられる.コンペティションでは,通常,複数のタスクと言語毎に分けられたトラックが存在する.参加チームごとに参加タスクおよびトラックを選択し,レギュレーションに従ってシステムを構築する.例えば,翻訳タスクであれば,最終的に人手により翻訳品質の評価がおこなわれ,システムの順位付が決定する.
現在,WMTにて様々な翻訳関連タスクが実施されているが,年々タスクが増減する中で,ニュース翻訳タスク(News Translation Task)は,2006年の第一回のワークショップからほぼ同じルールで毎年欠かさず続けられているWMTコンペティションを代表する伝統的なタスクである.これまでに多くの参加チームが機械翻訳システムの翻訳品質を競い合い,その中で多くの翻訳技術が培われてきた.機械翻訳の研究開発の発展においては大きな役割と存在感をもって世界中の翻訳研究者に認知されている.実際,ACL,EMNLPといった自然言語処理の最難関国際会議はもちろんのこと,NeurIPS, ICML, ICLR, AAAI, IJCAIといった機械学習や人工知能分野の最難関国際会議に採録される機械翻訳関係の論文のほとんどがWMTの配布データを使って実験をおこなっている.コンペティション参加システムやその後続の研究成果と性能を比較することで,それぞれの提案法の効果を示してきた.
このように世界中の機械翻訳の研究者/開発者が直接的または間接的に関わるWMT ニュース翻訳タスクは,その性質上,良好な成績を得ることが一種のステータスとなり得る.そのこともあって,毎年多くのチームがコンペティションに参加している.
3. WMT-2020参加トラックの結果
Team Tohoku-AIP-NTTは,2020年11月に開催されたWMT-2020のニュース翻訳タスクにおいて,英語からドイツ語(En-De),ドイツ語から英語(De-En),日本語から英語(Ja-En),英語から日本語(En-Ja)の4言語対の翻訳トラックに参加し,その全てで翻訳品質の人手評価において一位(同率含む)を獲得した[1, 2].また,ニュース翻訳において競争が激しいDe-EnおよびEn-Deの2トラックにおいては,自動評価指標(BLEUスコア)でも一位を獲得し[3],後の言語学の専門家(professional linguists)による評価でも,他のシステムよりも本システムの結果が総じて好ましいという結果も得られた[4].更に,言語学者による言語現象別の翻訳品質評価(複単語表現,固有名詞,機能語.動詞の時制など)においても,他のシステムを上回る最良の評価となった[5].
このように,複数のトラックで弊チームが事実上の一位3を獲得したことは,機械翻訳分野における日本のプレゼンス向上にも貢献したと考えている.
4. なぜ良好な結果が得られたのか
参加システムは,昨今広く用いられている,いわゆるTransformerをベースとしている.その意味においては独自の技術を使ったわけではなく,他のチームもほぼ同じ方法論やモデルを使っている.では,なぜ弊チームのシステムが他のチームより相対的によい結果が得られたのか?については,いくつかの要因が挙げられるが,総じて一言で言うと「頑張った」ということになるかもしれない.
最先端の技術をただ「知っている」ことと「実際にやる」ことには,大きな隔たりがあり,実際にやってみて初めて知る難しさや,そこから得られる経験的な知見がある.その観点で言うと,チームメンバー全員がそれまでの研究活動において大規模データに対する処理への耐性や,Transformerを効果的に使う知見を事前に得ていたことが大きな要因と考えている.そのため,最初から概ね全員が同じような感覚で作業を進めることができた.また,過去の実験で培った効果的な実験計画の方法論が確立しており,効率的に試行錯誤やハイパーパラメタの探索が行えたことも要因だと言える.
5. 参加システムの要点
2020年2月29日にデータが公開され,そこからシステム作成に入った.データの正規化やトークン区切りの話題から始まり,モデル構成を考えつつベースモデル(逆翻訳用)の学習をおこない,並行してハイパーパラメタ調整をする,といった感じにシステム開発を続けていき,最終的に7月1日に評価データの最終投稿をした.実質4ヶ月間の試行錯誤の結果になる.詳細なシステム構成などは,弊チームのWMTにおけるシステム論文を参考されたい[1].また,AAMT/Japio特許翻訳研究会が主催する「特許情報シンポジウム」にて本システムに関する講演を既に行っており, 詳細なシステム構成に関する発表資料を一般公開している[6].
現在の機械翻訳の主流は,いわゆるEnd-to-end型のニューラルネットワーク(以下ニューラル翻訳モデルと表記)である.ニューラル言語モデルに相当するニューラル翻訳モデルのデコーダによる高い文章再現能力により,かなり流暢で自然さの高い文章が生成できる.これは,従来の統計翻訳と比べてニューラル翻訳モデルを用いる大きなメリットとして真っ先に挙げられる点である.もう一つ,従来の統計翻訳と比べて,一つのニューラルネットワークにより翻訳が実現できる点も,処理工程を簡略化する観点で大きなメリットと考えられている.
しかし,コンペティションに参加する場合は,その様相は一変する.ニューラル翻訳モデルを用いる場合でも,純粋に翻訳品質を向上するには,単一のニューラル翻訳モデルよりも,モデルを複数用意し,それらを組み合わせることや,補助モジュールを組み合わせることが非常に効果的で翻訳品質を飛躍的に高めることが経験的に知られている.つまり,コンペティションでよい成績を獲得するには,様々なモデルの組み合わせの知見を一つずつきっちり導入し,その少しずつの積み上げの結果得られる大幅な品質向上を実現する作業が必要になる.以下に,参加システムの構成図を示す.
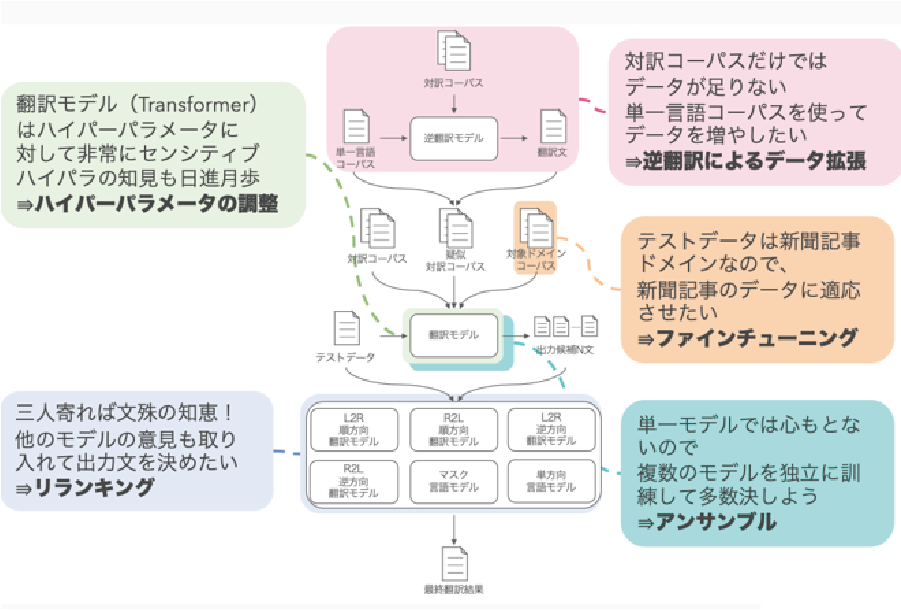
6. 参加システムの要点
実際に最終的な参加システムに導入されなかったが,システム開発の過程で試したいくつもの方法論がある.例えば,情報量指標に基づいたデータ選択を用いて,逆翻訳によって生成したデータも含めて,学習に効果の高そうなデータのみを選別し,それ以外の効果が薄い,或いは,悪影響のあると考えられるデータを学習データから除外するといった試みもおこなった.しかし,いくつかの取り組みは,検証段階で効果がでないことが確認され,やむなく参加システムからは外した.
実際には,こういったネガティブな結果に対する知見も実際にやってみることで初めて得られるものである.特に今回は,データが小規模である場合に効果的だと思われていた方法論も,扱うデータが大規模になるとほとんどその効果が見られなくなるといった現象が多く散見された.そのため,効果を期待して導入したいくつかの方法論(その中にはオリジナルの方法論も含む)が尽く利用できず,複雑なことを狙うよりも,データおよびモデルの大規模化がと言った堅実かつ最も単純な方法論が最も効果的だった.ある意味,とても味気ない結果となった.
7. 参加システムの要点
コンペティションにはレギュレーションが存在し,参加者が基本的に一定の条件下で競い合う.よって,現在の自分たちの技術レベルを確認することができる.また,良い成績を得れば,それが世界最先端の技術を持っていることの証明にもなる.そして,全く無名の研究者や組織であったとしても,コンペティションで圧倒的によい結果を得れば,その分野で一目おかれる存在に一足跳びになることができる.この観点からも,若手の研究者や開発者,または,規模の小さい企業などは,名を売るために挑戦するのも悪くはない選択と考えられる.しかし,最も重要なのは,システム構築の過程で得られる経験や知見であり,単に「知識として知っている」から実際に取り組んで「経験として知っている」へと昇華する良い場である点だと考えている.この経験が,その後の研究や開発の中で大きな武器となる.今後も組織横断的にモチベーションの高いチームを構築し,定期的にWMTに参加していきたいと考えている.
注釈
1 以降の節では基本的に常体により記述する.
2 2016年と言えば,ちょうどSennrichらのsubword [7]や逆翻訳(back-translation)[8] が登場してニューラル翻訳が更に効果的であることが示された年である. WMTにおいてもニューラル翻訳が主流になる契機となった.
3 WMTでは公式にシステムの順位を公表しているわけではないので,前述の評価結果の事実から「事実上の一位」という言い回しとしている.
参考文献
[1] Shun Kiyono, Takumi Ito, Ryuto Konno, Makoto Morishita, Jun Suzuki. “Tohoku-AIP-NTT at WMT 2020 News Translation Task”, In Proceedings of WMT-2020, pp. 145–155, 2020. [2] Loïc Barrault, Magdalena Biesialska, Ondřej Bojar, Marta R. Costa-jussà, Christian Federmann, Yvette Graham, Roman Grundkiewicz, Barry Haddow, Matthias Huck, Eric Joanis, Tom Kocmi, Philipp Koehn, Chi-kiu Lo, Nikola Ljubešić, Christof Monz, Makoto Morishita, Masaaki Nagata, Toshiaki Nakazawa, Santanu Pal, Matt Post, Marcos Zampieri, “Findings of the 2020 Conference on Machine Translation (WMT20)”, In Proceedings of WMT-2020, pp. 1–55, 2020. [3] 英語-ドイツ語,ドイツ語-英語間の翻訳品質の自動評価(BLEUスコア)で一位を獲得した根拠http://wmt.ufal.cz/newstest2020-de-en/
http://wmt.ufal.cz/newstest2020-en-de/ [4] Nitika Mathur, Johnny Wei, Markus Freitag, Qingsong Ma, Ondřej Bojar. “Results of the WMT20 Metrics Shared Task”, In Proceedings of WMT-2020, pp. 688–725, 2020. [5] Eleftherios Avramidis, Vivien Macketanz, Ursula Strohriegel, Aljoscha Burchardt, Sebastian Möller. "Fine-grained linguistic evaluation for state-of-the-art Machine Translation", In Proceedings of the WMT-2020, pp. 346–356, 2020. [6] 第6回特許情報シンポジウム
プログラム:
http://aamtjapio.com/symposium.html
スライド:
https://speakerdeck.com/butsugiri/ji-jie-fan-yi-konpeteisiyoncan-jia-bao-gao [7] Rico Sennrich, Barry Haddow, Alexandra Birch. “Neural Machine Translation of Rare Words with Subword Units”, In Proceedings of ACL-2016, pp. 1715–1725, 2016. [8] Rico Sennrich, Barry Haddow, Alexandra Birch. “Improving Neural Machine Translation Models with Monolingual Data”, In Proceedings of ACL-2016, pp. 86–96, 2016.



























































