マンガ機械翻訳への招待
石渡 祥之佑
Mantra株式会社
1. はじめに
このたびはAAMT長尾賞という大変名誉ある賞を授与いただき誠にありがとうございます.Mantra株式会社(以下,Mantra)は,マンガをはじめとする娯楽作品の多言語展開を加速することを目的とし2020年に設立されたスタートアップです.現在,Mantraでは独自のマンガ機械翻訳エンジンを搭載したCATツール「Mantra Engine」や,多言語化されたマンガを活用した外国語学習サービス「Langaku」の開発を行っています.本稿では,マンガ翻訳の現状やその自動化に向けた技術的挑戦,当該領域におけるMantraの取り組みを紹介します.
2. マンガ海外展開における課題
日本マンガの市場は国内外合わせて約6,126億円 [1] と大規模ですが,翻訳され日本国外で出版される作品点数は全体のわずか10%程度と言われています.この理由の一つとして,マンガ翻訳に高い時間的・金銭的コストがかかる点が挙げられます.マンガ翻訳は作品の文化的背景に対する深い理解や高度な創造性を要するだけでなく,「吹き出し」領域の塗りつぶしや翻訳済テキストの配置といった煩雑な画像処理も含むクリエイティブなタスクであり,その遂行にはどうしても複数人の専門家(たとえば翻訳者,チェッカー,デザイナ)間の連携が必要となります.結果,翻訳コストは高くなり,限られた出版社の一部の雑誌,さらにその中でもごく一部の作品が,いくつかの言語に翻訳されるに留まっています.
限られたマンガしか正規に翻訳・出版されない状況の中で,正規に翻訳されていない作品を世界中のマンガファンが独自にスキャン・翻訳し,無償でオンライン頒布する「海賊版」の存在が問題視されています.こうしたファンは「自分が好きな作品をもっと多くの人に読んでほしい」という純粋な動機で翻訳・配信に取り組むケースがほとんどではあるものの,海賊版の存在によって正規に翻訳されるマンガの販売機会が毀損されるという問題点があります.たとえば,米国における日本マンガの海賊版被害額は年間1.3兆円に達する [2]といわれています.正規版がないから海賊版が作られ,海賊版があるために正規版が売れにくく,結果国内外の出版社は大規模なマンガの翻訳出版に乗り出しにくい,という悪循環に陥ってしまっています.
Mantraはこの問題を解決するためにマンガ翻訳の生産性向上を目指し,マンガに特化した機械翻訳エンジンの研究開発や,マンガ翻訳ツール「Mantra Engine」の提供を行っています.以降,3節以降ではこれらの取り組みについて述べます.
3. マンガ翻訳自動化における技術的挑戦
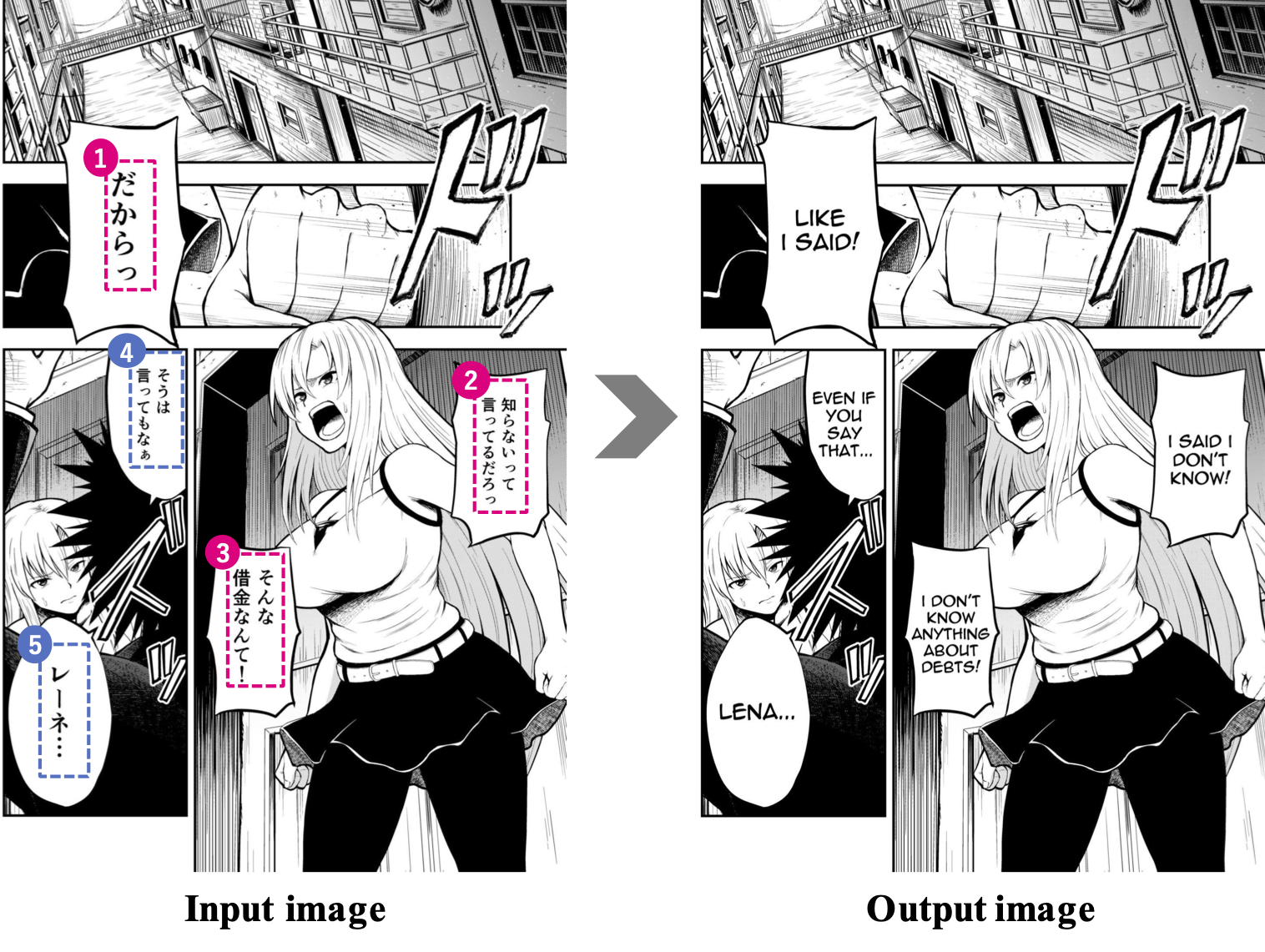
近年,産業翻訳の領域において機械翻訳が翻訳作業の効率化に大きく寄与した一方で,マンガ翻訳への機械翻訳導入は未だ進んでいません.私たちは,これがマンガ翻訳の難しさに起因すると考えています.たとえばマンガでは(1)「コマ」や「吹き出し」の配置にしたがってテキストが非規則的に配置されるため文脈情報を抽出しにくい,(2)会話文のため省略される語が多い,(3)キャラクタや場面によって独特な言い回しが発生するといった性質から,高精度な機械翻訳の実現が困難です.たとえば図1に示すように,単一の文が複数の吹き出しに分割されている場合が多くあります.そのため,吹き出しごとに独立して翻訳するのではなく,図1①〜③のように適宜語順を入れ替えながら日英翻訳を行う必要があります.また,吹き出し内のテキストは全て会話文であることから,原言語である日本語では,多くの場合主語や目的語が省略されます.さらに,倒置表現や語尾の「っ」など,マンガ特有の表現が多用されます.マンガのこうした性質は,どれも機械翻訳システムの精度を著しく低下させるものです.こうした問題を解決するために,私たちはマンガに特化した対訳コーパス構築と翻訳アルゴリズムの開発を同時に進めていく必要があると考えています.
4. マンガ機械翻訳の実現に向けて
前節で述べたマンガ翻訳自動化の難しさをふまえ,本節ではMantraがこれまでに取り組んできた高精度なマンガ機械翻訳エンジンを実現するための取り組みを紹介します.
マンガ翻訳評価用データセット「Open Mantra」
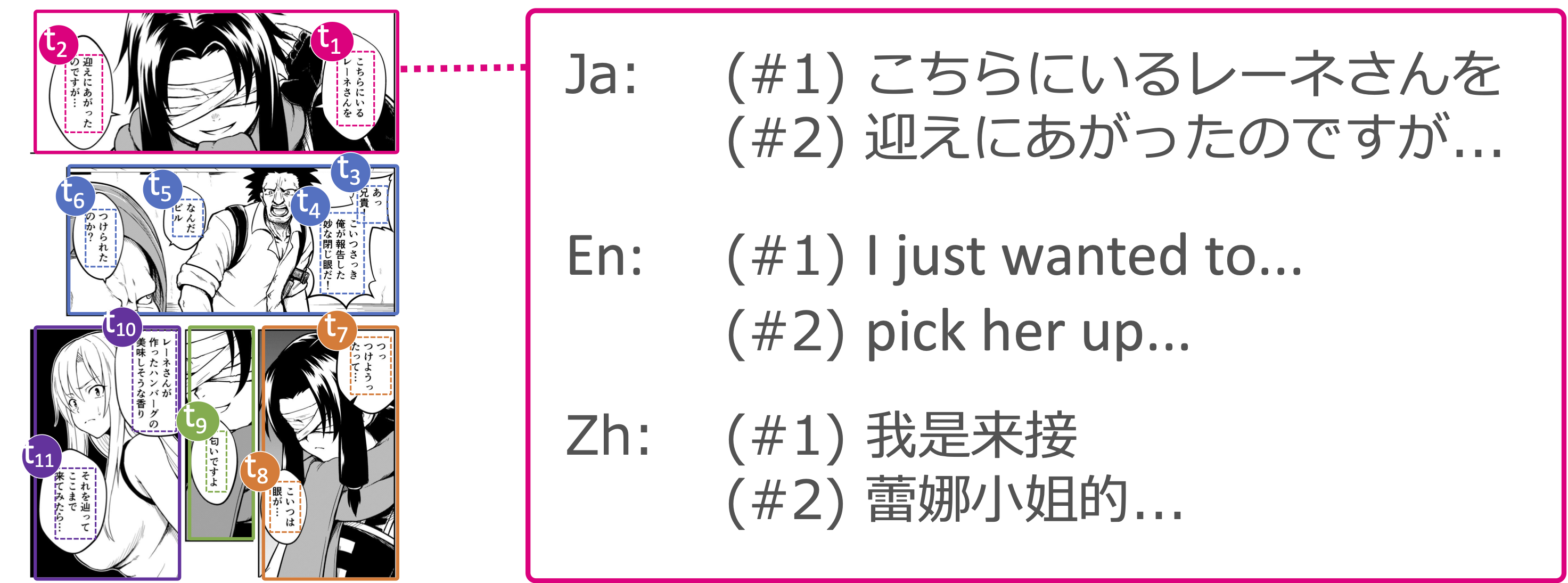
翻訳エンジンの開発や性能改善において,定量的な評価を実施するためのデータセットの存在は必要不可欠です.前節で述べたように,多くのマンガは他ドメインのテキストと異なる性質をもつため,マンガ翻訳エンジンを評価するためにはマンガ専用の評価基盤が必要となります.著者らが本研究に着手した2018年当時,マンガ翻訳エンジンの性能を手軽に評価する方法は存在しませんでした.そこで,私たちは複数人の漫画家の協力のもと,5ジャンル(恋愛,ミステリー,ファンタジー,日常,バトル)の作品を含む世界初のマンガ翻訳評価用データセット「Open Mantra」を研究用途に公開しました.図2に示すように,このデータセットでは日本語のマンガ画像にコマや吹き出しの座標が人手で付与され,各セリフは翻訳者によって英語と中国語に翻訳されています.このデータセットを公開することで,マンガ機械翻訳の研究開発を行う全ての研究者・技術者に翻訳エンジンの評価基盤を提供することができました.
シーンに基づくマンガ機械翻訳
3節で述べたように,マンガでは単一の文が複数の吹き出しに分割されて表現されることが多くあります.プロの翻訳者らは吹き出し単位で独立して翻訳を行うのではなく,目的言語版のマンガとして自然になるよう,必要に応じて吹き出しのテキスト順序を入れ替えながら翻訳を行います.また,マンガの吹き出しは単純にページ内の上から下,右から左に配置されているわけではなく,コマ割り(コマの分割や配置)の制約を受けて配置されています.マンガに慣れ親しんだ読者にとっては,脳内でコマ割りを理解して吹き出しの順序を推定し,適切な塊ごとにテキストを区切りながら読むことは無意識に行うことができる容易なタスクですが,計算機でこの処理を自動化する方法は自明ではありません.
私たちはこの問題に対し,コマを一つの「シーン」と捉え,シーンごとにテキストをまとめて翻訳する手法を提案しました.図3にこの手法の概要を示します.まず入力された画像からコマの領域を推定し,コマごとにその中に含まれるテキストを認識します.コマ内のテキストの順序を推定した後,この順序にしたがって各吹き出し内のテキストを特殊トークンで連結し,まとめて翻訳を行います.一般に文脈を考慮する機械翻訳 [3] [4] [5]手法では,文脈窓(考慮する周辺テキストの文数)が1文〜2文などと固定されることが多いですが,マンガではコマによってセリフの多寡が大きく変化します.そこで文脈として用いる吹き出しの数は固定せず,コマごとに動的に変化させます.
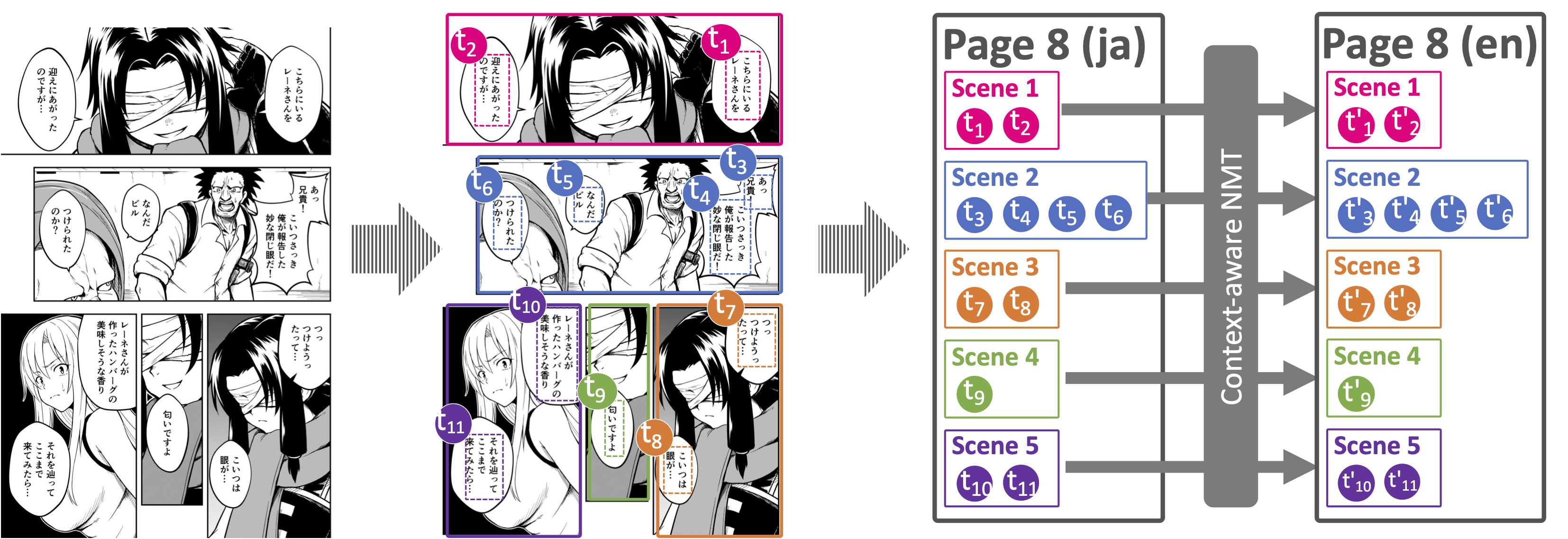
図4に従来手法(吹き出しごとに独立に翻訳)と提案手法(シーンごとにまとめて翻訳)の例をそれぞれ示します.このように考慮すべき文脈の範囲を適切に設定することで,より自然な訳出が可能になります.

マンガ画像からの対訳コーパス自動抽出
マンガ独特の表現を正しく翻訳したり,前述した文脈範囲を動的に変化させる手法を実現したりするためには,プロの翻訳者が翻訳したマンガコーパスを用いて翻訳エンジンを訓練する必要があります.しかしながら,現状マンガに特化した対訳コーパスは存在せず,また一から人手で構築することもコスト的に現実的ではありません.そこで,Mantraは原言語・目的言語で描かれたマンガ画像から,自動的に文脈情報のついた対訳コーパスを抽出する手法を提案しました.
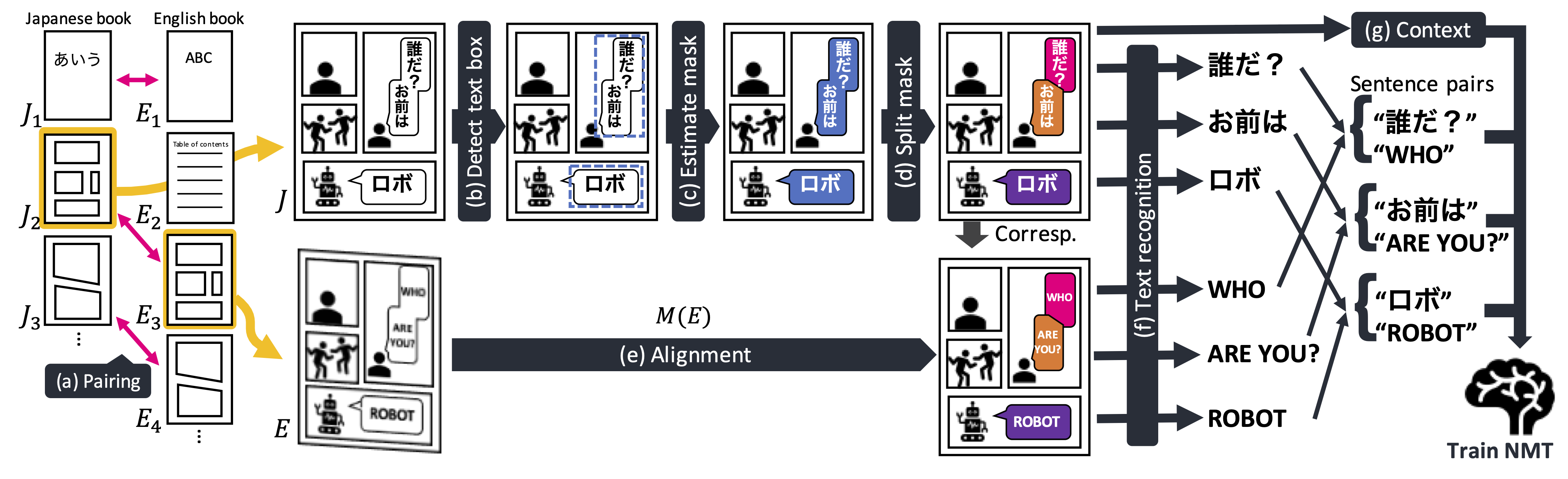
翻訳版のマンガは,原語版のマンガと比較して(1)表紙や目次,扉などが挿入・削除されてページ数が異なっている,(2)画像サイズやアスペクト比が調整されていることがあるため,単純なルールベース処理で対訳ページを見つけることはできません.さらに,ページ単位で対応関係が取れたとしても,縦書き・横書き等のレイアウトの違いが存在することで,文単位の対訳関係を抽出することは容易ではありません. そこで,Mantraは図5に示す対訳データ抽出パイプラインを設計し,この問題の解決を試みました.このパイプラインでは,入力される日本語のマンガ画像に対し,まず物体検出アルゴリズムにより吹き出し領域の矩形を検出(図5b),これを吹き出し単位に分割(c~d)します.続いて画像検索手法を用いて当該ページと対応する目的言語のページを抽出(a)し,対応する原言語ページとピクセルレベルでアライメントを取ります(e).最後に原言語,目的言語それぞれの文字認識エンジンによって,吹き出し領域ごとに対訳テキストを抽出します.この仕組みによって,翻訳済マンガ画像の集合から全自動で対訳コーパスを構築する枠組みが完成し,大規模データで高精度なマンガ翻訳エンジンを訓練することが可能になりました.
5. マンガ翻訳ワークフローへのMT導入
前節で述べた様々な取り組みにより,マンガ翻訳エンジンの開発・評価・改善を実施できるようになりました.本節では,このエンジンを翻訳現場で使用するためのクラウドツール「Mantra Engine」を紹介します.
図6にMantra Engineの翻訳エディタ画面を示します.図中左では,入力された日本語画像から自動検出された吹き出し領域がオレンジ色の枠で表示されています.図中右には吹き出しごとに機械翻訳の結果が表示され,その内容を翻訳者やチェッカーが編集できる仕組みが用意されています.
また,Mantra Engineの利用者は訳文を編集するだけでなく,機械翻訳に反映される用語集の整備や写植作業(文字のレイアウトやフォントの切り替えなど),原文・翻訳文の全文検索,他の作業者とのコミュニケーションや編集権限の管理など,マンガ翻訳に係るあらゆる作業を当ツール内で完結することができます.
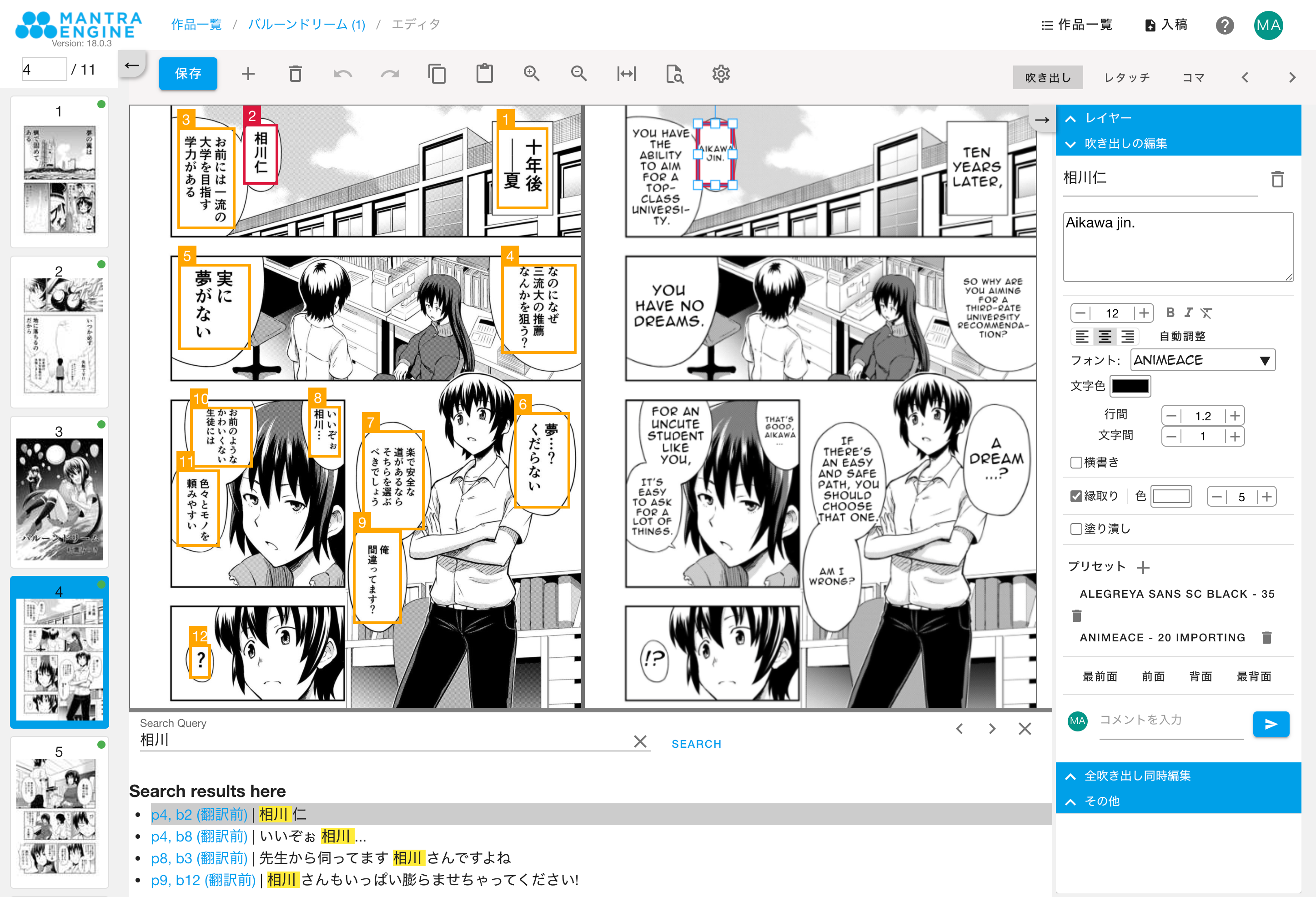
Mantra Engineは既に複数の出版社や翻訳業者,マンガ配信事業者に導入され,幾つかのマンガ作品については,実際に多言語同時配信の現場でも使われはじめています.
6. おわりに
「世界の言葉で、マンガを届ける。」これが,Mantra設立時に著者らが掲げたスローガンです.しかしながら,この目標に向けて2人の大学院生がはじめたマンガ機械翻訳の研究は未だ萌芽的な段階にあります.より多くのマンガをより多くの人に,リアルタイムに届けられるようにするためには,まだ解決すべき技術的課題が多く残されています.技術が継続的に発展,普及していくためには,単一の企業や研究室が独自に研究開発を進めるだけではなく,多くの研究者や技術者が参加し,議論を重ねる研究コミュニティが形成されることが極めて重要です.本稿をきっかけに読者の皆さまがマンガ機械翻訳という未開の(そしてとても興味深い!)技術領域に興味を持ち,参入いただけることを私たちは強く期待しております.
また,Mantraのマンガ機械翻訳研究に惜しみない支援をくださった東京大学の吉永直樹先生,相澤清晴先生,松井勇佑先生,古田諒佑先生,東京理科大学の谷口行信先生,ならびに谷口研の学生の皆さま,誠にありがとうございました.このような名誉ある賞を授与くださったAAMTの皆さま,推薦いただいた先生方にも心より御礼申し上げます.



























































