Translation and Description Methods for Multilingual Text Understanding
Shonosuke Ishiwatari
Mantra Inc.
1. Abstract
The development of Web technologies has been rapidly accelerating human communication and sharing of knowledge. The massive amount of text on the new communication platforms or knowledge sources often consists of documents in several domains and multiple languages. In order to obtain fresh and diverse information from multilingual and diverse text sources such as Twitter, Wikipedia, or arXiv, we need to cope with language barrier while also paying attention to domain differences.
Let us move on to the general topic of natural language processing. Machine translation, as one of the most promising applications of natural language processing, has been playing an essential role in overcoming the language barrier. The recent development of machine learning techniques and huge annotated corpora have considerably improved the performance of machine translation. In the face of the increasing use of multilingual platforms and knowledge sources, can machine translation help us understand the real text data in various domains? Can machine translation be applied to languages pairs whose vocabulary and grammar are significantly different (such as English vs. Japanese)? More generally, can machine directly help humans understand text written in unfamiliar domains/languages? These are the central topics of this thesis.
To answer the above questions, we propose (i) an instant domain adaptation method, (ii) an accurate translation method for English-to-Japanese translation, and (iii) an automatic description method for unknown phrases.
i) Instant domain adaptation for Statistical Machine Translation.
To translate text in various domains, the most basic method is domain adaptation. Most studies on domain adaptation require supervised in-domain resources such as parallel corpora or in-domain dictionaries. The necessity of supervised data has made such methods difficult to adapt to practical machine translation systems. In this thesis, we thus propose a method that adapts translation models without in-domain parallel corpora. Our method improves out-of-domain translation from Japanese to English by 0.5-1.5 BLEU score.
ii) Accurate translation method for English-to-Japanese translation.
English-to-Japanese translation is more difficult than other language pairs such as English-to-German or English-to-French translations. This is mainly because (1) Japanese sentence has much more words in a sentence compared to English, and (2) Japanese is a free-word-order language. To cope with these problems, we propose a chunk-based decoder for neural machine translation. Our method improves English-to-Japanese translation by 0.93 BLEU score and achieves state-of-the-art performance on the WAT '16 translation task.
iii) Automatic description generation for unknown phrases.
Even if a text is translated perfectly, or written in our familiar languages, it is still common for humans to become stuck on unfamiliar words or phrases. To help humans understand unknown phrases which are not included in hand-crafted dictionaries, we undertake a task of describing a given phrase in natural language based on its contexts. In contrast to the existing methods, our model appropriately takes important clues from contexts and achieves state-of-the-art performance in four description generation datasets.
The three methods are designed to help humans understand real multilingual text where (1) the target domain is unknown, (2) the source language may extremely differ from the users' languages, and (3) the users may be unfamiliar with the words/phrases in the text. Due to limitations of the paper length, in the rest of this article, we focus on describing the third part of the above contributions.
2. Introduction
When we read news text with emerging entities, text in unfamiliar domains, or text in foreign languages, we often encounter expressions (words or phrases) whose senses we are unsure of. In such cases, we may first try to figure out the meanings of those expressions by reading the surrounding words (local context) carefully. Failing to do so, we may consult dictionaries, and in the case of polysemous words, choose an appropriate meaning based on the context. Learning novel word senses via dictionary definitions is known to be more effective than contextual guessing (Fraser, 1998; Chen, 2012). However, very often, hand-crafted dictionaries do not contain definitions of expressions that are rarely used or newly created. Ultimately, we may need to read through the entire document or even search the web to find other occurances of the expression (global context) so that we can guess its meaning.
Can machines help us do this work? Ni and Wang (2017) have proposed a task of generating a definition for a phrase given its local context. However, they follow the strict assumption that the target phrase is newly emerged and there is only a single local context available for the phrase, which makes the task of generating an accurate and coherent definition difficult (perhaps as difficult as a human comprehending the phrase itself). On the other hand, Noraset et al. (2017) attempted to generate a definition of a word from an embedding induced from massive text (which can be seen as global context). This is followed by Gadetsky et al. (2018) that refers to a local context to disambiguate polysemous words by choosing relevant dimensions of their word embeddings. Although these research efforts revealed that both local and global contexts are useful in generating definitions, none of these studies exploited both contexts directly to describe unknown phrases.
In this study, we tackle a task of describing (defining) a phrase when given its local and global contexts. We present LOG-CaD, a neural description generator (Figure 1) to directly solve this task. Given an unknown phrase without sense definitions, our model obtains a phrase embedding as its global context by composing word embeddings while also encoding the local context. The model therefore combines both pieces of information to generate a natural language description.
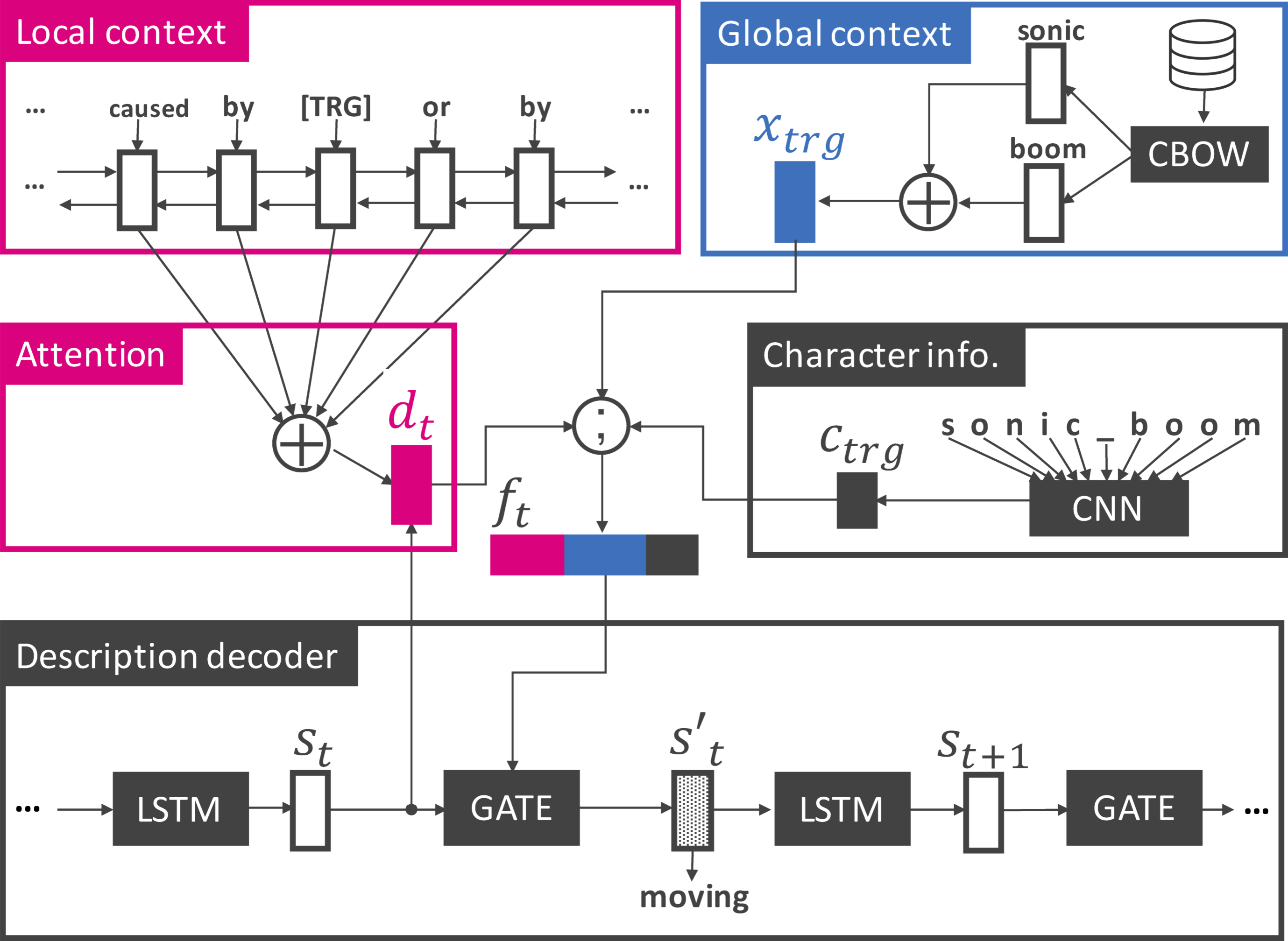
Considering various applications where we need definitions of expressions, we evaluated our method with four datasets including WordNet (Noraset et al., 2017) for general words, the Oxford dictionary (Gadetsky et al., 2018) for polysemous words, Urban Dictionary (Ni and Wang, 2017) for rare idioms or slangs, and a newly-created Wikipedia dataset for entities.
The contributions of this work are as follows:
- We setup a general task of defining phrases given their contexts. This task is a generalization of three related tasks (Noraset et al., 2017; Ni and Wang, 2017; Gadetsky et al., 2018) and involves various situations where we need definitions of unknown phrases (Section 3).
- We propose a method for generating natural language descriptions for unknown phrases with local and global contexts (Section 4).
- As a benchmark to evaluate the ability of the models to describe entities, we build a largescale dataset from Wikipedia and Wikidata for the proposed task. We release our dataset and the code to promote the reproducibility of the experiments (Section 5).
- The proposed method achieves the state-of-the-art performance on our new dataset and the three existing datasets used in the related studies (Noraset et al., 2017; Ni and Wang, 2017; Gadetsky et al., 2018) (Section 6).
3. Context-aware Phrase Description Generation
In this section, we define our task of describing a phrase in a specific context. Given an undefined phrase Xtrg={xj,⋯,xk} with its context X={x1,⋯,xI} (1 ≤j ≤k ≤I), our task is to output a description Y={y1,⋯,yT}. Here, Xtrg can be a word or a short phrase and is included in X. Y is a definition-like concrete and concise sentence that describes the Xtrg.
For example, given a phrase “sonic boom” with its context “the shock wave may be caused by sonic boom or by explosion,” the task is to generate a description such as “sound created by an object moving fast.” If the given context has been changed to “this is the first official tour to support the band’s latest studio effort, 2009’s Sonic Boom,” then the appropriate output would be “album by Kiss.”
The process of description generation can be modeled with a conditional language model as
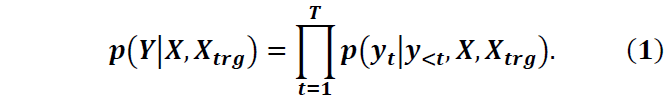
4. LOG-CaD: Local & Global Context-aware Description Generator
In this section, we describe our idea of utilizing local and global contexts in the description generation task, and present the details of our model.
4.1 Local & global contexts
When we find an unfamiliar phrase in text and it is not defined in dictionaries, how can we humans come up with its meaning? As discussed in Section 2, we may first try to figure out the meaning of the phrase from the immediate context, and then read through the entire document or search the web to understand implicit information behind the text.
In this paper, we refer to the explicit contextual information included in a given sentence with the target phrase (i.e., the X in Eq. (1)) as “local context,” and the implicit contextual information in massive text as “global context.” While both local and global contexts are crucial for humans to understand unfamiliar phrases, are they also useful for machines to generate descriptions? To verify this idea, we propose to incorporate both local and global contexts to describe an unknown phrase.
4.2 Proposed model
Figure 1 shows an illustration of our LOG-CaD model. Similarly to the standard encoder-decoder model with attention (Bahdanau et al., 2015; Luong and Manning, 2016), it has a context encoder and a description decoder. The challenge here is that the decoder needs to be conditioned not only on the local context, but also on its global context. To incorporate the different types of contexts, we propose to use a gate function similar to Noraset et al. (2017) to dynamically control how the global and local contexts influence the description.
Local & global context encoders. We first describe how to model local and global contexts. Given a sentence X and a phrase Xtrg, a bidirectional LSTM (Gers et al., 1999) encoder generates a sequence of continuous vectors H={h1⋯,hI} as
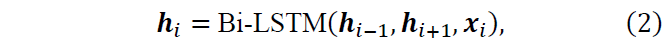
where xi is the word embedding of word xi. In addition to the local context, we also utilize the global context obtained from massive text. This can be achieved by feeding a phrase embedding xtrg to initialize the decoder (Noraset et al., 2017) as
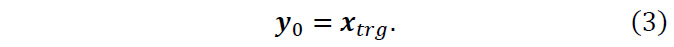
Here, the phrase embedding xtrg is calculated by simply summing up all the embeddings of words that consistute the phrase Xtrg. Note that we use a randomly-initialized vector if no pre-trained embedding is available for the words in Xtrg.
Description decoder. Using the local and global contexts, a description decoder computes the conditional probability of a description Y with Eq. (1), which can be approximated with another LSTM as
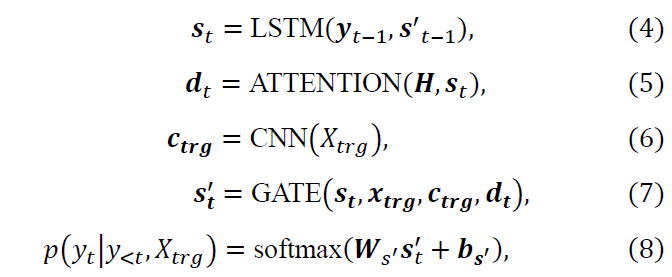
where st is a hidden state of the decoder LSTM (s0 =0→), and yt−1 is a jointly-trained word embedding of the previous output word yt−1. In what follows, we explain each equation in detail.

Attention on local context. Considering the fact that the local context can be relatively long (e.g., around 20 words on average in our Wikipedia dataset introduced in Section 5), it is hard for the decoder to focus on important words in local contexts. In order to deal with this problem, the ATTENTION(·) function in Eq. (5) decides which words in the local context X to focus on at each time step. 𝒅t is computed with an attention mechanism (Luong and Manning, 2016) as
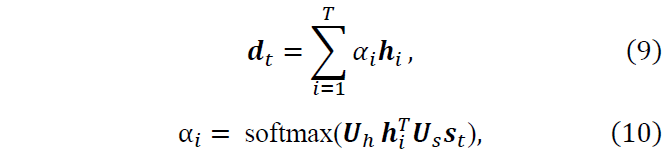
where 𝑼h and 𝑼s are matrices that map the encoder and decoder hidden states into a common space, respectively.
Use of character information. In order to capture the surface information of Xtrg, we construct character-level CNNs (Eq. (6)) following (Noraset et al., 2017). Note that the input to the CNNs is a sequence of words in Xtrg, which are concatenated with special character “_,” such as “sonic_boom.” Following Noraset et al. (2017), we set the CNN kernels of length 2-6 and size 10, 30, 40, 40, 40 respectively with a stride of 1 to obtain a 160-dimensional vector 𝒄trg.
Gate function to control local & global contexts. In order to capture the interaction between the local and global contexts, we adopt a GATE(·) function (Eq. (7)) which is similar to Noraset et al. (2017). The GATE(·) function updates the LSTM output 𝒔t to 𝒔′t depending on the global context 𝒙trg, local context 𝒅t, and character-level information 𝒄trg as
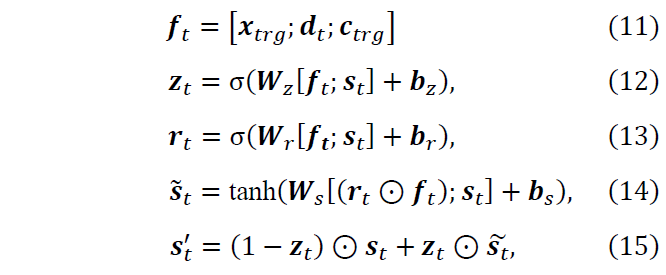
Where σ(⋅), ⊙ and ; denote the sigmoid function, element-wise multiplication, and vector concatenation, respectively. 𝑾∗ and 𝒃∗ are weight matrices and bias terms, respectively. Here, the update gate 𝒛t controls how much the original hidden state 𝒔t is to be changed, and the reset gate 𝒓t controls how much the information from 𝒇t contributes to word generation at each time step.
5. Wikipedia Dataset
Our goal is to let machines describe unfamiliar words and phrases, such as polysemous words, rarely used idioms, or emerging entities. Among the three existing datasets, WordNet and Oxford dictionary mainly target the words but not phrases, thus are not perfect test beds for this goal. On the other hand, although the Urban Dictionary dataset contains descriptions of rarely-used phrases, the domain of its targeted words and phrases is limited to Internet slang.
In order to confirm that our model can generate the description of entities as well as polysemous words and slang, we constructed a new dataset for context-aware phrase description generation from Wikipedia and Wikidata which contain a wide variety of entity descriptions with contexts. The overview of the data extraction process is shown in Figure 2. Each entry in the dataset consists of (1) a phrase, (2) its description, and (3) context (a sentence).
For preprocessing, we applied Stanford Tokenizer to the descriptions of Wikidata items and the articles in Wikipedia. Next, we removed phrases in parentheses from the Wikipedia articles, since they tend to be paraphrasing in other languages and work as noise. To obtain the contexts of each item in Wikidata, we extracted the sentence which has a link referring to the item through all the first paragraphs of Wikipedia articles and replaced the phrase of the links with a special token [TRG]. Wikidata items with no description or no contexts are ignored. This utilization of links makes it possible to resolve the ambiguity of words and phrases in a sentence without human annotations, which is a major advantage of using Wikipedia. Note that we used only links whose anchor texts are identical to the title of the Wikipedia articles, since the users of Wikipedia sometimes link mentions to related articles.
6. Experiments
Datasets. We evaluate our method by applying it to describe words in WordNet (Miller, 1995) and Oxford Dictionary, phrases in Urban Dictionary and Wikipedia/Wikidata. For all of these datasets, a given word or phrase has an inventory of senses with corresponding definitions and usage examples. These definitions are regarded as groundtruth descriptions.
Models. We implemented four methods: (1) Global (Noraset et al., 2017) that access the pretrained embeddings of the phrase to be described, but has no ability to read the local context; (2) Local (Ni and Wang, 2017) which consists of the encoders to read the local context (i.e., usage examples of the terms); (3) I-Attention (Gadetsky et al., 2018), and the (4) LOG-CaD. Similar to our model, I-Attention utilizes both local and global contexts. Unlike our model, on the other hand, it does not use character information to predict descriptions. Also, it uses the local context only to disambiguate the phrase embedding instead of encoding the local context directly to predict descriptions. All the models are implemented with the PyTorch framework (Ver. 1.0.0).
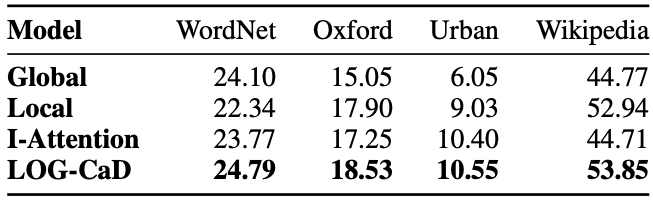
Automatic evaluation. Table 1 shows the BLEU (Papineni et al., 2002) scores of the output descriptions. We can see that the LOG-CaD consistently outperforms the three baselines in all four datasets. This result indicates that using both local and global contexts help describe the unknown words/phrases correctly. While the I-Attention also uses local and global contexts, its performance was always lower than the LOG-CaD. This result shows that using local context to predict description is more effective than using it to disambiguate the meanings in global context. In particular, the low BLEU scores of Global and I-Attention models on Wikipedia dataset suggest that it is necessary to learn to ignore the noisy information in global context if the coverage of pre-trained word embeddings is extremely low. We suspect that the Urban Dictionary task is too difficult and the results are unreliable considering its extremely low scores and high ratio of unknown tokens in generated descriptions.
Manual evaluation. To compare the proposed model and the strongest baseline in Table 1 (i.e., the Local model), we performed a human evaluation on our dataset. We randomly selected 100 samples from the test set of the Wikipedia dataset and asked three native English speakers to rate the output descriptions from 1 to 5 points as: 1) completely wrong or self-definition, 2) correct topic with wrong information, 3) correct but incomplete, 4) small details missing, 5) correct. The averaged scores are reported in Table 2. Pair-wise bootstrap resampling test (Koehn, 2004) for the annotated scores has shown that the superiority of LOG-CaD over the Local model is statistically significant (p < 0.01).

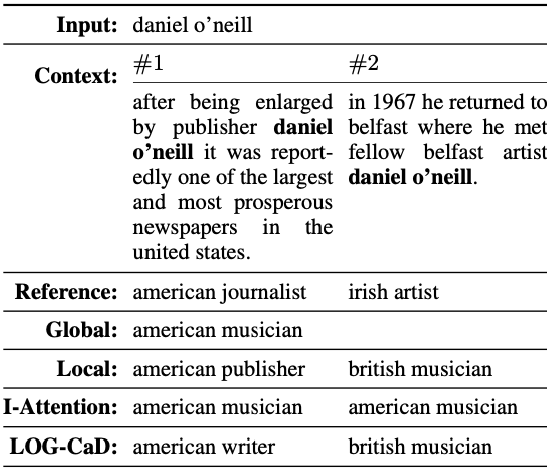
Qualitative Analysis. Table 3 shows a word in the WordNet, while Table 4 show the examples of the entities in Wikipedia. When comparing the two datasets, the quality of generated descriptions of Wikipedia dataset is significantly better than that of WordNet dataset. The main reason for this result is that the size of training data of the Wikipedia dataset is 64x larger than the WordNet dataset (14k entries vs. 887k entries).

For both examples in the two tables, the Global model can only generate a single description for each input word/phrase because it cannot access any local context. In the Wordnet dataset (Table 3), only the I-Attention and LOG-CaD models can successfully generate the concept of "remove" given the context #2. This result suggests that considering both local and global contexts are essential to generate correct descriptions. In our Wikipedia dataset (Table 4), both the Local and LOG-CaD models can describe the word/phrase considering its local context. As shown in the table, both the Local and LOG-CaD models could generate "american" in the description for "daniel o'neill" given "united states" in context #1, while they could generate "british" given "belfast" in context #2. On the other hand, the I-Attention model could not describe the two phrases, taking into account the local contexts.
7. Conclusions
This paper sets up a task of generating a natural language description for an unknown phrase with a specific context, aiming to help us acquire unknown word senses when reading text. We approached this task by using a variant of encoder-decoder models that capture the given local context with the encoder and global contexts with the decoder initialized by the target phrase’s embedding induced from massive text. We performed experiments on three existing datasets and one newly built from Wikipedia and Wikidata. The experimental results confirmed that the local and global contexts complement one another and are both essential; global contexts are crucial when local contexts are short and vague, while the local context is important when the target phrase is polysemous, rare, or unseen.
As future work, we plan to modify our model to use multiple contexts in text to improve the quality of descriptions, considering the “one sense per discourse” hypothesis (Gale et al., 1992).
Acknowledgements
This article is a reconstruction of the author’s PhD thesis “Translation and Description Methods for Multilingual Text Understanding.” I am grateful to my PhD advisors at the UTokyo, Prof. Masaru Kitsuregawa, Prof. Masashi Toyoda, and Prof. Naoki Yoshinaga for guiding me during the long journey to the PhD. I would also like to express my gratitude to my mentors at CMU, Prof. Graham Neubig and Dr. Hiroaki Hayashi for their substantial contributions to the paper. Finally, I would also like to thank all the researchers who reviewed and recommended the thesis to AAMT Nagao Student Award.
References
Ion Androutsopoulos and Prodromos Malakasiotis. 2010. A survey of paraphrasing and textual entailment methods. Journal of Artificial Intelligence Research, 38:135–187.
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In Proceedings of the Third International Conference on Learning Representations (ICLR).
Yuzhen Chen. 2012. Dictionary use and vocabulary learning in the context of reading. International Journal of Lexicography, 25(2):216–247.
Michael Connor and Dan Roth. 2007. Context sensitive paraphrasing with a global unsupervised classifier. In Proceedings of the 18th European Conference on Machine Learning (ECML), pages 104–115.
Katrin Erk. 2006. Unknown word sense detection as outlier detection. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics (NAACL), pages 128–135.
Carol A. Fraser. 1998. The role of consulting a dictionary in reading and vocabulary learning. Canadian Journal of Applied Linguistics, 2(1-2):73–89.
Artyom Gadetsky, Ilya Yakubovskiy, and Dmitry Vetrov. 2018. Conditional generators of words definitions. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Short Papers, pages 266–271.
William A. Gale, Kenneth W. Church, and David Yarowsky. 1992. One sense per discourse. In Proceedings of the workshop on Speech and Natural Language, HLT, pages 233–237.
Felix A. Gers, Jurgen Schmidhuber, and Fred Cum-¨ mins. 1999. Learning to forget: Continual prediction with lstm. In Proceedings of the Ninth International Conference on Artificial Neural Networks (ICANN), pages 850–855.
Philipp Koehn. 2004. Statistical significance tests for machine translation evaluation. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 388–395.
Jey Han Lau, Paul Cook, Diana McCarthy, Spandana Gella, and Timothy Baldwin. 2014. Learning word sense distributions, detecting unattested senses and identifying novel senses using topic models. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 259–270.
Minh-Thang Luong and Christopher D. Manning. 2016. Achieving open vocabulary neural machine translation with hybrid word-character models. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), pages 1054–1063.
Nitin Madnani and Bonnie J. Dorr. 2010. Generating phrasal and sentential paraphrases: A survey of data-driven methods. Computational Linguistics, 36(3):341–387.
Aurelien Max. 2009. Sub-sentencial paraphrasing by´ contextual pivot translation. In Proceedings of the 2009 Workshop on Applied Textual Inference, pages 18–26.
Aurelien Max, Houda Bouamor, and Anne Vilnat.´ 2012. Generalizing sub-sentential paraphrase acquisition across original signal type of text pairs. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pages 721–731.
George A Miller. 1995. Wordnet: a lexical database for english. Communications of the ACM, 38(11):39– 41.
Roberto Navigli. 2009. Word sense disambiguation: A survey. ACM COMPUTING SURVEYS, 41(2):1–69.
Ke Ni and William Yang Wang. 2017. Learning to explain non-standard English words and phrases. In Proceedings of the 8th International Joint Conference on Natural Language Processing (IJCNLP), pages 413–417.
Thanapon Noraset, Chen Liang, Larry Birnbaum, and Doug Downey. 2017. Definition modeling: Learning to define word embeddings in natural language. In Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI), pages 3259–3266.
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of 40th Annual Meeting of the Association for Computational Linguistics (ACL), pages 311–318.
Advaith Siddharthan. 2014. A survey of research on text simplification. International Journal of Applied Linguistics, 165(2):259–298.



























































