みらい翻訳のこれまでとこれから
森 勇二
株式会社みらい翻訳
1. はじめに
みらい翻訳は「RBMTとSMT等を統合した機械翻訳プラットフォームの開発とB2Bビジネスの実現」を評価頂き第11回(2016年)AAMT長尾賞を受賞しました。本稿では受賞から5年間の事業面、技術面の変遷を中心に紹介します。
2. 長尾賞受賞当時のみらい翻訳
我々が長尾賞を受賞した2016年、無料/有料問わず機械翻訳サービスは統計的機械翻訳(Statistical MT; SMT)が主流でした。みらい翻訳は国立研究開発法人情報通信研究機構(NICT)よりSMTのエンジン供与を受け、ルールベース機械翻訳(Rule-Based MT; RBMT)と組み合わせたハイブリッド構成や事前並べ替え技術により日英のベース精度を高め、用途に特化したカスタマイズモデルを載せた機械翻訳エンジンの提供を行っていました。2014年の創業以来初めての単年度黒字を達成したのもこの年でした。しかしながら、当時の単純な延長線上に今のみらい翻訳の姿はありませんでした。
現在の機械翻訳技術の主流であるニューラル機械翻訳(Neural Machine Translation; NMT)は2014年に原型となるエンコーダ・デコーダモデルが提案されましたが、実用的には我々が長尾賞を受賞した直後の2016年9月に発表されたGoogle NMT(GNMT)のインパクトが大きく、この時期を境に我々もいつNMTを出す予定なのかという問い合わせを頂くようになりました。それまではNMT固有の課題も多く実用化はまだ先のことだと考えていましたが、急ピッチでの実用化を余儀なくされました。
3. 機械翻訳SaaS企業への転身
2017年、SMTベースの機械翻訳エンジンの新規販売を停止し、NICTとの共同研究の成果を実用化する形でNMTエンジンの自社開発を開始しました。同年、ビジネス向け文書翻訳SaaSのMirai Translator®の開発に着手、2017年12月にリリースしました。現在、NTTコミュニケーションズ社へのOEM提供によるCOTOHA® Translatorも含め、これらのサービスがみらい翻訳の主力事業となっています。 Mirai Translatorは我々の得意とする日本語を中心とした翻訳精度の高さを軸に、一般ビジネスユーザに使いやすいシンプルなUI、ISO27001、27017を取得するなど高いセキュリティで運用していることを強みとして一定以上の規模の企業を中心に導入が進んでおり、数万人規模の大規模導入となるようなケースも増えています。翻訳機能としてはテキスト翻訳、ファイル翻訳の2種類を提供しており、ファイル翻訳はファイル形式としてtxt, docx, xlsx, pptx, pdfをサポートしています。また、ユーザ辞書、翻訳メモリによるカスタマイズが可能となっています。
機械翻訳エンジンの内製化および自社サービスの開発・運用体制の構築により2017-2018年度は大幅な赤字を出すこととなりましたが、2019年度に再度黒字化を達成しました。
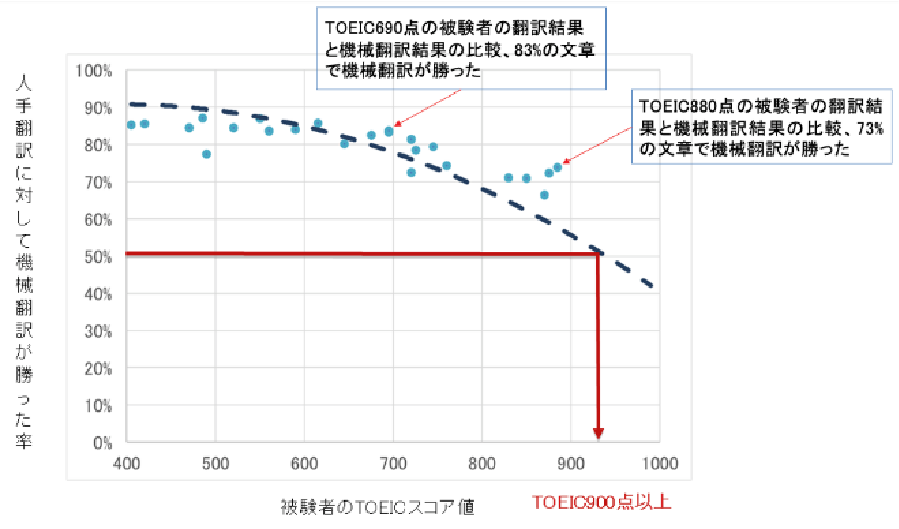
創業以来、対外的に翻訳精度を伝える指標の一つとしてTOIECスコアを用いてきました。これは簡単に言うとTOIECスコアが既知の被験者と機械翻訳とで日英翻訳の精度を競わせ、ネイティブ評価者による勝敗が均衡する箇所を機械翻訳のスコアとするもので、長尾賞受賞当時は約650点でした。SMTをベースとした漸近的な進化を想定した創業時の2018年における目標は800点でしたが、NMTにより2017年に900点、2018年には960点を達成しました。評価として意味を成さなくなってきていることと、評価自体にコストがかかることから最近はこの評価を行なっていません。前述の通り、創業当初のみらい翻訳は機械翻訳エンジンのカスタマイズを事業の中心としていましたが、ベース精度の向上により現在はカスタマイズサービスの引き合いはかなり少なくなっています。
NMTにより機械翻訳精度、とりわけ翻訳結果の流暢さは大幅に向上しましたが、仕組み上訳抜け/過剰生成や数値の間違い等のエラーは発生しやすくなりました。特にビジネスの現場では固有名詞や数値の間違いは深刻な問題を引き起こす可能性があります。そのため、みらい翻訳では全てをニューラルネットワークで解決するのではなく、言語に特化したルールの作り込みも行っています。多数の対応言語を誇るWeb翻訳サービスとの方向性の違いの一つと考えています。
4. ビジネスシーンでのDX、さらにその先へ
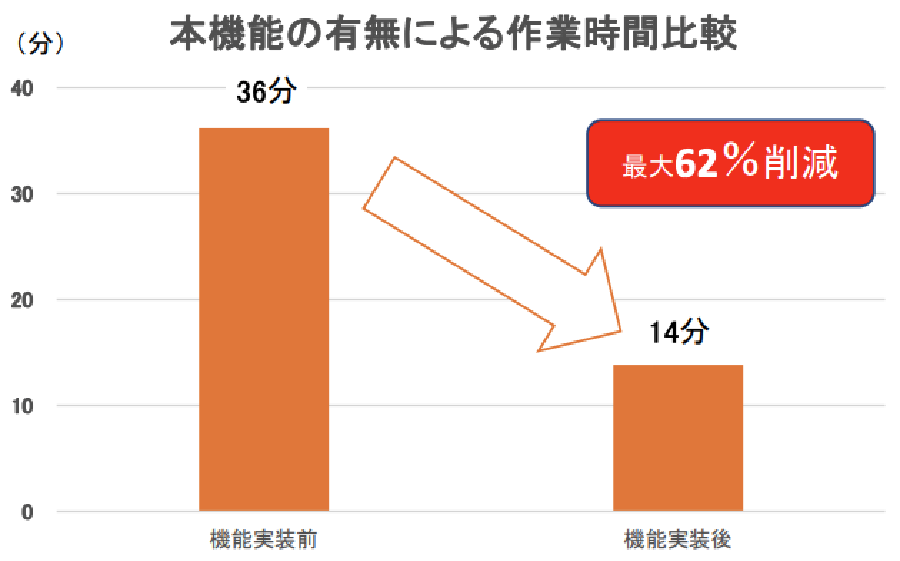
現在、我々はMirai Translator®を多言語業務をこなす日系企業をメインターゲットとした生産性向上ソリューションと位置付けています。生産性向上のためには翻訳精度の向上以外にもやるべきことが数多くあります。一例を挙げると、ファイル翻訳の装飾保持です。RBMTやSMTと異なりNMTでは原文と訳文の間の単語対応が明確でなく、当初のファイル翻訳では原文の装飾情報は翻訳の際に捨ててしまっていました。一方で翻訳して資料を仕上げるという観点では装飾も重要な情報で、仮に翻訳が完璧であったとしても失われた装飾情報の復元には後編集の工程でそれなりの稼働がかかります。そこで、翻訳と装飾保持を同時に解くモデルを開発しました。本機能により、ファイル翻訳の後編集工程にかかる時間を最大で62%削減することに成功しました。
NMT、特にアテンション付きエンコーダ・デコーダモデルの登場により機械翻訳の社会実装が大幅に進みました。これまで述べてきた通り、事業における当面の主戦場は企業における文書翻訳の生産性向上を如何に実現していくか、にあります。一方で我々が企業ビジョンとして掲げる「言語バリアフリーの世界の実現」に向けては個人向けサービスや音声翻訳サービスなど顧客セグメント、応用領域の両方を広げていく必要があります。みらい翻訳は今後も機械翻訳の社会実装により、言語バリアフリーの実現を推進していきます。



























































