【JTF40周年特別企画】2021年度第1回JTF関西セミナー
機械翻訳とは何か? どこから来て、どこへいくのか?
石岡映子
JTF常務理事
株式会社アスカコーポレーション
1. はじめに
2021年4月27日(火)14:00~16:00、Zoomで開催された当イベントを報告する。一般社団法人日本翻訳連盟(JTF)40周年を祝う最初のイベントとして、JTF副会長でもある個人翻訳者の高橋聡氏と、東京大学大学院情報理工学系研究科客員研究員の中澤敏明氏にご登壇いただき、機械翻訳(MT)の進化を踏まえ、翻訳業界や翻訳者がMTとどう向き合い、付き合っていくのか、産業としての翻訳へのMTの影響や意味、役割、今後の可能性についてお話を伺った。昨年出版された『機械翻訳:歴史・技術・産業』(森北出版社)に基づいて(セミナータイトルは、同書の帯から引用)翻訳された高橋氏と解説を執筆された中澤先生お二人のつながりでセミナーが実現した。
高橋氏からは、そもそも翻訳とは何か、翻訳者は今後MTとどう向き合っていくのか、一部の仕事はMTに奪われていくという現実と、翻訳者の仕事の必要性と可能性など。
中澤氏からは、最新のニューラル機械翻訳の技術を、学習のデモを交えてわかりやすく説明いただいた。なぜ機械翻訳は間違えるのか、これから精度は上がっていくのか、など。お二人のご講演とパネルディスカッションの3部構成である。
2. 第1部 訳書を通じて個人翻訳者が考えた機械翻訳(高橋聡氏)

(1) 訳書の紹介とハイライト
第1章 はじめに
第2章 翻訳をめぐる諸問題
第3章 機械翻訳の歴史の概要
第4章 コンピューター登場以前
第5章 機械翻訳のはじまり
第6章 1966年のALPACレポートとその影響
第7章 パラレルコーパスと文アラインメント
第8章 用例ベースの機械翻訳
第9章 統計的機械翻訳と単語アラインメント
第10章 セグメントベースの機械翻訳
第11章 統計的機械翻訳の課題と限界
第12章 ディープラーニングによる機械翻訳
第13章 機械翻訳の評価
第14章 産業としての機械翻訳
第15章 結論として:機械翻訳の未来
解 説 2020年時点でのニューラル機械翻訳(中澤敏明:東京大学特任講師)

(2) MTに対する多言語世界の要請
欧州議会内部では2013年時点で予算3.3億ユーロの翻訳の93%が人力で行われているままで、増加する処理量と予算削減のためにさまざまな取り組みが進んでいるとのことである。カナダの天気予報では1970年からMT訳が導入されており、信頼性も高いという事実は驚異的である。世界の特許市場での状況を考えると、多言語世界を知ることで、MTに対する要請の背景が見えてくる。2000年代最初まで“日本は特殊”とされ、翻訳予算がついていたが、アジアの翻訳拠点は香港や上海に移り、今やグローバルの翻訳市場の一角でしかなくなり、特殊扱いは崩壊してしまった。
(3) MTに対する翻訳者の思い
翻訳者のMTに対するスタンスは人により異なる。MTの動向とは無縁に自分の翻訳を続けるという人がいるが、逆に、AIを積極的に導入したいという人もおり、大多数はその間で揺れている。
翻訳をする動機もさまざまである。好きだから、楽しいからという動機と、生活の手段として仕事にしているという動機があるが、大多数はその両端に振り切れるのではなく、中間にいる。このスタンスによってMTへの考え方は異なる。
そもそも翻訳とは何か。人間の翻訳者は、何通りもの訳出パターンを頭に思い浮かべ、文種、文体、文脈などの条件に合わせて絞り込んでいく。MTに慣れたら何通りも翻訳案を考えることは必要なくなる。
情報としての翻訳は、TM期を経てMTに移行していく。その中間にポストエディットが存在する。コンテンツとしての翻訳には、少なくとも当面は人間の翻訳が必要である。
(4) 個人翻訳者のこれから
淘汰と変化は必ず起こる。多くの人がやっている"裾野"の翻訳の仕事はなくなる可能性がある。翻訳者として自分の道は自分が考えるしかない。
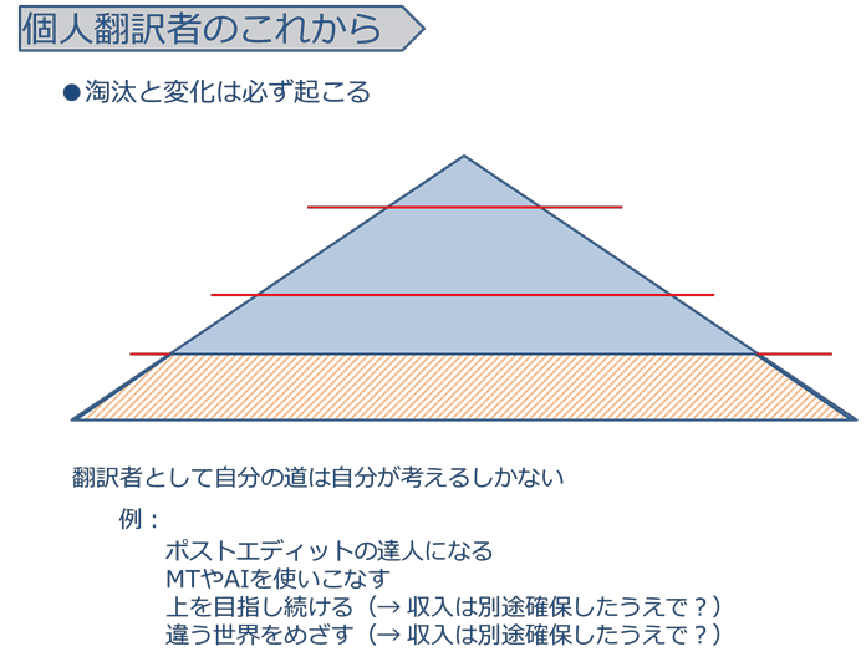
どの道を選んでもそこに上下や貴賤はないが、進んだ先で見える世界はまったく違うものになる。それはどんな形で翻訳に関わりたいかによって決まるはずである。
(5) MTの扱われ方
検証を経ずに安易にMTを使ったり、売ったりすることは問題である。災害警報の誤訳の問題が過去に起こったが、ここでは「情報としての翻訳」としてすら十全に機能していない。これには、社会全体の取り組みが必要である。「MTなんて使いものにならない」ではなく、「使えるようにするにはどうすればいいのか」を考える、啓発することが必要で、翻訳者にも関わってほしい、と結んだ。
講演後の質疑応答では、ポストエディットの単価の妥当性、機械翻訳の台頭で翻訳者が搾取されているのではないか、などの質問が出た。一部の翻訳会社の「機械翻訳でコストダウンと納期短縮が可能!」といった売り方は場合にもよるとの回答。「機械翻訳は全然使えない。機械翻訳を使うと翻訳ができなくなる」などのSNSでの意見は極論だと思う、と答えた。
3. 第2部 機械翻訳の現状と課題、可能性(中澤敏明氏)
(1) NMTの訓練デモと最新の技術動向
リアルタイムでNMTの訓練デモが行われた。京都に関するデータが題材として使われた。対訳コーパス対して、Fairseq(Facebook AIが開発・公開しているフリーツール)を用い、SentencePieceでサブワードに分割した教師データで訓練。サブワードとは、未知語や複合語を単語と文字の中間的な単語に分割することで、あまりに低頻度な語を学習させることを回避し、語彙サイズを最適化する方法である。サブワードの手法にSentencePieceを使うことで、文から直接単語分割を学習することができるため、事前の手動での分割処理が不要になる。
例)
通常の単語分類
本山|は|、|足利|義満|に|より|建立|さ|れた|京都|の|相国|寺
サブワード
本|山|は|、|足利義|満|により|建立|された|京都|の|相|国|寺
(足利義〇の人がたくさんいることから、「足利義」までをひとまとまりとなる)
サブワードを用いると固有名詞や専門用語などが分割されるだけでなく、数字やURLなど翻訳が不要なものまでばらばらになってしまうため、一見翻訳する必要がないように見えるものであっても、誤訳が発生してしまう原因となってしまうという欠点がある。
次に、事前質問に対する解説をいただいた(一部抜粋)。
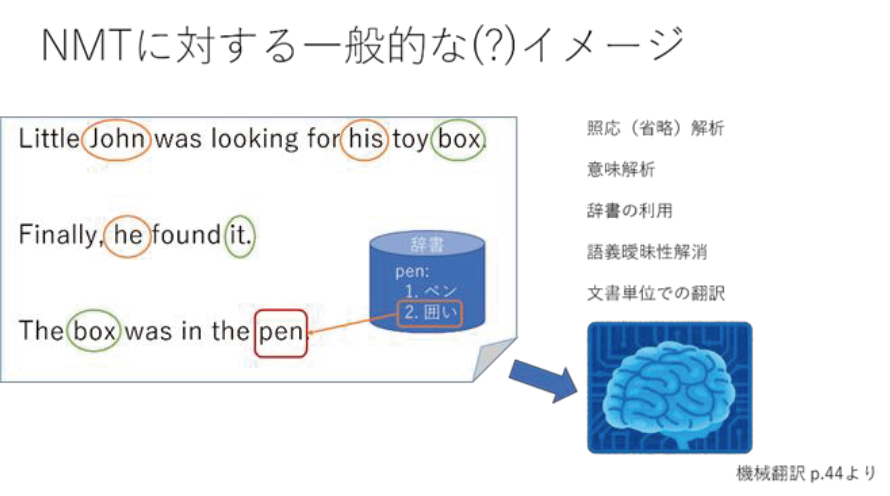
実際は、
Q1:
辞書にはアノテーションが重要だと思われますが、多義語やアノテーション付きの辞書は存在するのでしょうか?
A:現在は使わない。
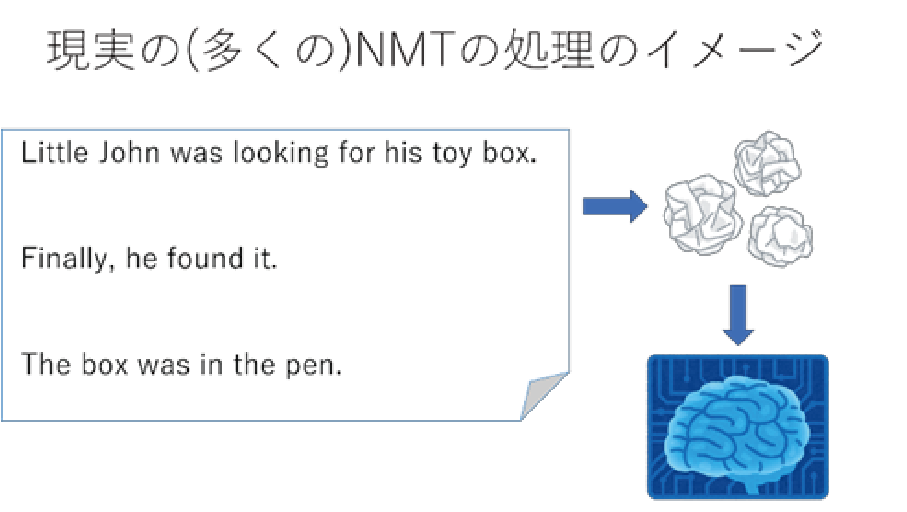
実際には、以下のような仕組みでNMTは処理される。
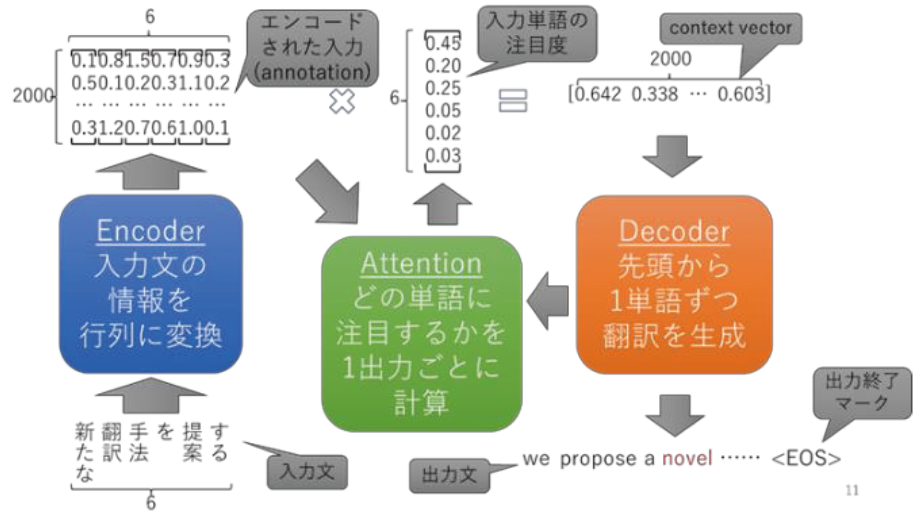
NMTの特徴として、NMTでは、入力文を「置き換える」ことで翻訳するのではなく、入力文を見ながら、翻訳文を作り出すため、流暢な翻訳になる。また、ベクトル表現(word embedding)を使うおかげで柔軟な翻訳が可能である。一方で、統計的機械翻訳(SMT)のときのように単語単位での対訳をモデルに組み込むことは容易ではなく、翻訳完了マークが出力されるまで翻訳が続くので、入力文を過不足なく翻訳できていないことがある。また、全然違う訳が出てしまうことを防げないのも短所の一つ(例:I come from Tunisia。 → ノルウェーの出身です[Arthur et al., 2016])。
Q2:
NMTの訳抜けの穴埋めをするために、ルールベース翻訳の結果と比較検証し、エラーを指摘するのはできないのか?
A:NMTでは入力と出力の対応をとれないので、ルールベースの出力と合わせることは困難。
Q3:
良質の対訳データを組み込むために施策は取られているか?
A:既存の対訳コーパスの人手クリーニングもしくは自動クリーニング、Webクロールデータに対する文アライメントや翻訳メモリの蓄積など。
Q4:
文単位でなくドキュメントの文脈も加味して翻訳できるMTもあるようだが、最新の動向や、選ぶポイントを教えてほしい。
A: DeepLは照応・省略解析なども行っており、文単位ではなく複数文のまとまりでの翻訳が可能。Google翻訳も最近、複数文のまとまりでの翻訳が可能になり、日進月歩なので実際に試すのが良い。
Q5:
敬語や口語の選択ができず、混ざった文章が出力させるのはなぜか?
A:訓練に使ったデータに両方が混じっているから。
Q6:人名や地名など、一般名詞と区別する技術はないのか?
A:語義曖昧性解消や固有表現抽出などの技術は独立して以前からあるが、NMTでそれらの技術を直接使うことはあまりなく、Transformerでは入力文ごとに単語のベクトル表現を計算するので、文脈に応じてより適切に語義を推定することが可能。
Q7:
感情の読み取りが必要な小説などではMTは使えないと言われているが、どうなのか?
A:数年以内にはできないが、10年後の可能性はゼロではない。そもそも人間の翻訳でも「正しい」翻訳は存在しない?
(2) MTの現状と課題
できることは徐々に増えてきている。省略や照応解析の利用、文書単位の翻訳や資源が乏しい言語の翻訳、マルチモーダル翻訳など。
しかし課題はまだまだ山積。訳抜け・湧き出し、否定・肯定誤り、訳語統一、代名詞誤り、対訳辞書の利用、ドメインアダプテーション、翻訳速度など、さまざまな問題点を日々改善している。
(3) MTの可能性
深層学習の限界はまだよくわかっていないが、NMTが出た当初の2014年より成長スピードが落ちている印象がある。NMTは人間が一生かけて読む文書量よりもはるかに多くの文に触れているので、人間の翻訳より良い訳を出すこともある。しかし、いつもよいわけでないので、チェックが必要である。
人手が不要もしくは最低限でよいという翻訳の需要は必ず存在するし、その割合は多くなるはず。MTが活かせるところは積極的に活かすべきだと思う。翻訳されなかったものが翻訳されるようになり、仕事を奪うのではなくサポートとして活用し、翻訳全体の生産性を向上するものになってほしい。
4. 第3部 パネルディスカッション「機械翻訳とは何か、どこへいくのか?」
モデレーター:石岡映子氏(JTF常務理事・関西委員長、株式会社アスカコーポレーション代表取締役)
石岡:弊社のクライアント対象のアンケートでは、8割の企業がMT導入済で、残りの2割の半分が検討中であった。JTFの最新の白書でも特許・医薬・工業が収入減、現場にMTが導入されたためと思われる。書籍のように人がやらないといけないところは伸びている。このような環境下でいくつかの課題を伺いたい。
まず、公共機関などでの間違ったMT表記についての問題はどうか?
高橋:社会全体で考えないといけない問題である。気になるのは、誤訳の情報を発信した後、当の公共機関がその後どうしたか、なぜか報道がない。反省し、改善しないといけないと思う。それには翻訳業界、JTFのような業界団体が先陣を切ってやっていくべきではないか?
石岡:受け止める側の観点はどうか?
中澤:オンラインのフリーソフトは自己責任において使用するのが普通であり、使用によって生じた損害は保障されない。そこに品質を求めることはナンセンスである。そういう教育を受けていないがためにリテラシーが低いことが問題であり、子どものころから教育するべきだ。また、フリーのものをどう使うかも考えるべき。
石岡:翻訳という仕事はなくなるのか。NMTになって導入が進み、実際収入減となっている。今後どうなっていくのか?
高橋:なくなっていく部分はある。その部分を担っていた人がこの先どうするかは、PEに移行する、人手でしかできない分野に挑戦するなど。全部なくなるわけではないが一部は確実になくなっていく。その前提で考えるべき。
石岡:MTをハンドリングする方面の人材不足も感じている。
中澤:翻訳が細分化されると、新たな需要が出てくる。コーパス、辞書の整理、これらもMTで使いやすい形にするにはリテラシー、プログラミングなど、これまでの翻訳者に求められるものとは異なった新たな職業ができる。純粋な翻訳者は減っても新たな関連の仕事が出てくる。
高橋:翻訳に関わるデータ整備の仕事については、翻訳メモリが出現した時代から整理の必要があった。当初はやっていたのが、この20年、ほぼ放置状態。チューニングしていれば、翻訳メモリの精度も上がっていたはずである。その反省から、翻訳やレビューもできるリンギスト、いろんな方面に目を配り、レビュー結果をもとにクライアントと交渉できる人が求められる。翻訳者とは違うかもしれないが重要な仕事である。
石岡:業界は、クライアントから受け取ったTMが適切でなかったとしても指摘してこなかった。TMの管理をできる人材は翻訳会社にとって欲しい人材である。翻訳者やチェッカーに、新しいキャリアパスという観点で挑戦してほしい。
石岡:グローバルの観点から、翻訳は未来への投資として重視されてきて、品質への期待は高い。一方、情報を早く出さなければならない時代、品質をどう考えたらいいか?
高橋:投資ならリターンが必要、リターンが見えづらいから企業も投資しない。翻訳者に十分な情報を提供せず、だから望むものが返ってこない。翻訳者の力不足でかたづけるのではなく、顧客と翻訳会社と翻訳者が品質を合意し、そこに結果が出れば投資につながるのでは。
中澤:そのとおり。マニュアルで売り上げが増えたかは計算できないし、将来がわからないからコストをかけられない。特にベンチャーなどでは予算もなく、製品のバージョンアップサイクルが早くて予算が取れないから機械翻訳になる。よりシビアにクライアントが必要とする品質をすりあわせコントロールすることへのLSPの役割は大きい。
石岡:目の前の納期ありきで、クライアントと必要な精度、品質をすりあわせていないことが多い。三者が合意をすることで、翻訳者、翻訳会社は商品として品質を担保し、クレームも減る。MTが浸透する中、改めて品質についてすりあわせするべき。
中澤:低い品質、安い見積もりにつけこむ人が出てくると、業界の首を絞めるので、適切に取り組むべきである。
質疑応答:
Q.自分の翻訳メモリのような小規模データセットで、既成のエンジンの出力はどれくらい変化するのか。
中澤:数万文、十万文ぐらいないと変わらない、数千文でもニッチな業界ですべてを網羅しているのならあり。翻訳したい文のバリエーションによる。特許文全体を翻訳したいのに工業のコーパスしか持っていないなら、自分でバランスをとってみてもらうしかない。
高橋:TM登場のときからそういう議論があって、メモリの扱いには注意が必要なのに、似たことが繰り返されそうな感じがする
Q.将棋や囲碁ではAIが人間に優っているのに、翻訳ではMTが人間を越えられないのはなぜか?
中澤:将棋や囲碁は正解があるが、翻訳は明快なゴールがないから、ゴールが決まっているほうがやりやすい
高橋:文芸翻訳のような正解のない翻訳で、MTが初音ミクのように、1つの個性になったらおもしろい。
中澤:そういう研究もある。たとえば太宰治風とか。人格を持たせるのはおもしろい。
5. 終わりに
今回のセミナーでMTと翻訳のことが結論付いたわけではない。継続的に正しい情報をもとに議論していくことが重要である。そこで中澤氏は、翻訳者と機械翻訳(の研究者)がお互いをもっと理解するための「翻訳と機械翻訳の座談会」というYouTubeチャンネルを開設された。
https://www.youtube.com/channel/UC4fiKKrfcvQY1dcZkjxfnHQ
今後はこのチャンネルで、翻訳と機械翻訳の未来を語り合いたい。
参考資料
- Thierry Poibeau『機械翻訳:歴史・技術・産業』(森下出版)
原題:“Machine Translation” (The MIT Press Essential Knowledge series) - 機械翻訳はどこに行くのか?『機械翻訳:歴史・技術・産業』山田優(AAMT Journal No.74)



























































