第8回アジア翻訳ワークショップ(WAT2021)開催報告
中澤 敏明
東京大学
1. はじめに
本稿ではWAT2021[1]の開催報告を行う。アジア翻訳ワークショップ(Workshop on Asian Translation, WAT)はアジア言語を中心とした評価型機械翻訳ワークショップであり、2014年に第1回(WAT2014)を開催して以降、毎年開催している。本稿の著者は初回からオーガナイザーの一人としてワークショップの運営を行っている。2016年の第3回(WAT2016)以降は自然言語処理の国際会議との併設ワークショップとして開催しており、2021年の第8回(WAT2021[1])はタイのバンコクで開催されたACL-IJCNLP 2021の併設ワークショップとして、2021年8月6日にオンラインで開催された。
ワークショップは様々な機械翻訳の評価タスクの実施に加えて機械翻訳に関する研究論文の募集も行っており、WAT2021では5件の研究論文と、ACL-IJCNLP2021から2件のfindings論文を採択した。採択した研究論文のタイトルを以下に示す。
- BTS: Back TranScription for Speech-to-Text Post-Processor using Text-to-Speech-to-Text
- Zero-pronoun Data Augmentation for Japanese-to-English Translation
- Evaluation Scheme of Focal Translation for Japanese Partially Amended Statutes
- Optimal Word Segmentation for Neural Machine Translation into Dravidian Languages
- Itihasa: A large-scale corpus for Sanskrit to English translation
また2件の招待講演も行われた。1件目はFacebook AIのFrancisco Guzmán氏およびAngela Fan氏により“Massively Multilingual Translation and Evaluation”というタイトルで行われ、2件目はカーネギーメロン大学のGraham Neubig氏により“Understanding and Improving Context Usage in Context-aware Translation”というタイトルで行われた。
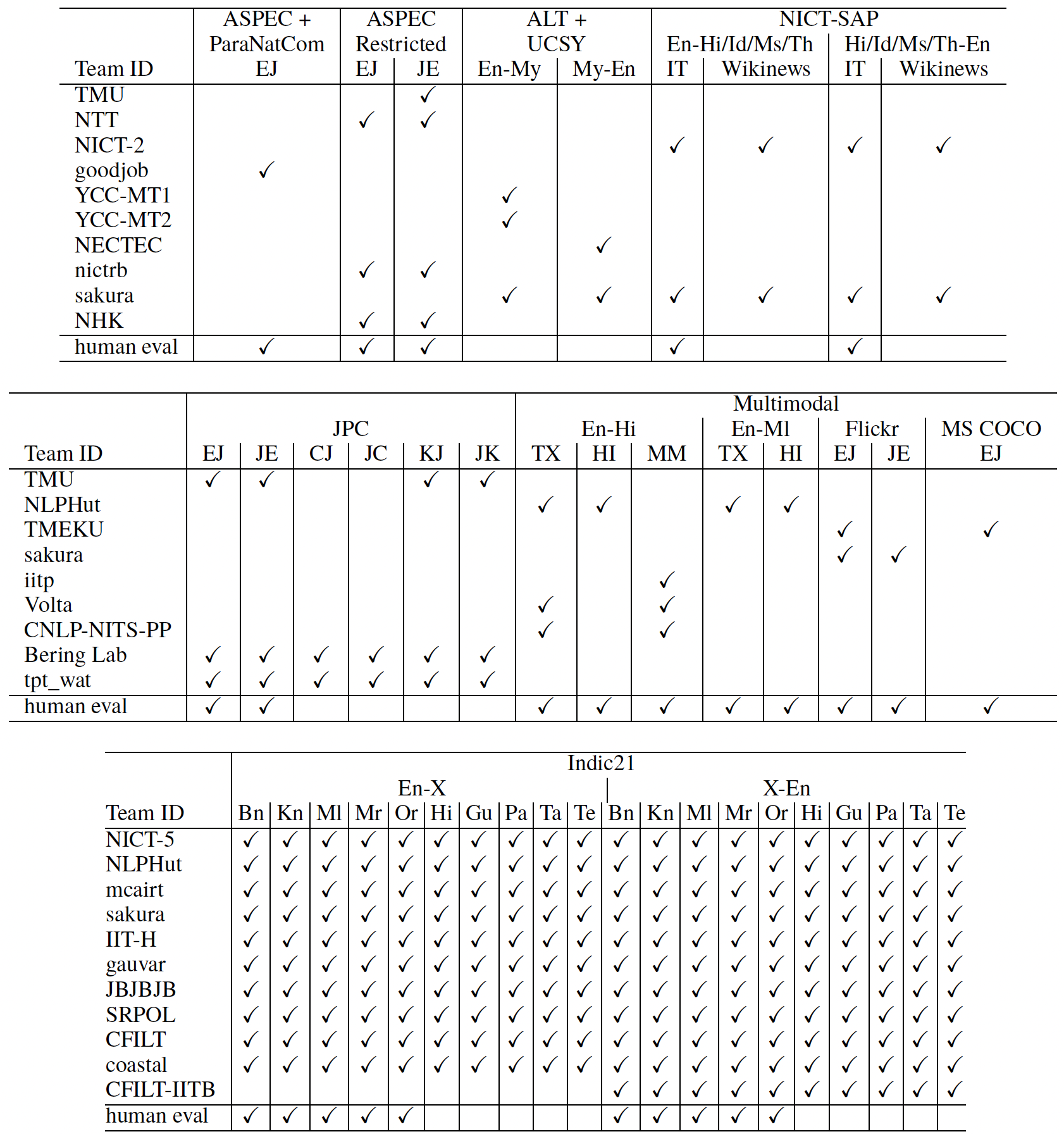
WAT2021では18の言語を対象とした14のshared taskが行われ、世界中から26のチームが参加した。表 1に参加者のリストを示す。なお表中でアスタリスクがついているチームは、構築したシステムの解説論文を提出しなかったことを表している。

昨年度に引き続き、海外はインドからの参加者が多かった。インド諸語を対象とした翻訳タスクにおいては扱う言語の数が年々増えており、インドの研究者を中心として活発に研究が進んでいるためであると思われる。他にも中国、韓国、シンガポール、タイ、ミャンマー、スイス、デンマークなどからの参加があり、国際化がより進んだワークショップとなっている。
WAT2021で新たに追加されたタスクは以下の通りである:
- 英語からマラヤーラム語(インドで話されている言語)へのマルチモーダル翻訳
- 曖昧性のある動詞を対象とした日英のマルチモーダル翻訳
- 10言語のインド諸語と英語間のマルチリンガル翻訳
- 使用するフレーズが指定された日英の制限翻訳タスク
表 2に各タスクの参加チームリストおよび人手評価を行ったタスク(表中のhuman evalにチェックがついているタスク)を示す。
2. 評価結果と得られた知見
2.1 特許翻訳タスク
特許翻訳タスクは特許庁より提供された特許対訳コーパスJPC1を用いて行われ、日英・日中・日韓の双方向の翻訳タスクで構成されている。翻訳評価は自動評価と人手評価を行った。自動評価尺度としてはBLEU[2]、RIBES[3]及びAM-FM[4]を用いている。AM-FMは正確さと流暢さの両方を考慮したような評価手法である。人手評価は特許庁が公開している「特許文献機械翻訳の品質評価手順」 2の中の「内容の伝達レベルの評価」に従って行った。これは機械翻訳結果が原文の実質的な内容をどの程度正確に伝達しているかを、人手翻訳の内容に照らして、下記 5 段階の評価基準で主観的に評価するものである。

日英・日韓には3チーム(TMU, Bering Lab, tpt_wat)が、日中には2チーム(Bering Lab, tpt_wat)が自動評価サーバーに翻訳結果を提出したが、人手評価用の翻訳結果を提出したのは1チーム(TMU)のみであった。また予算の都合上、実際に人手評価を行ったのは日英、英日タスク1チーム分のみである。図1に自動評価結果を、図2および図3に人手評価結果を示す。
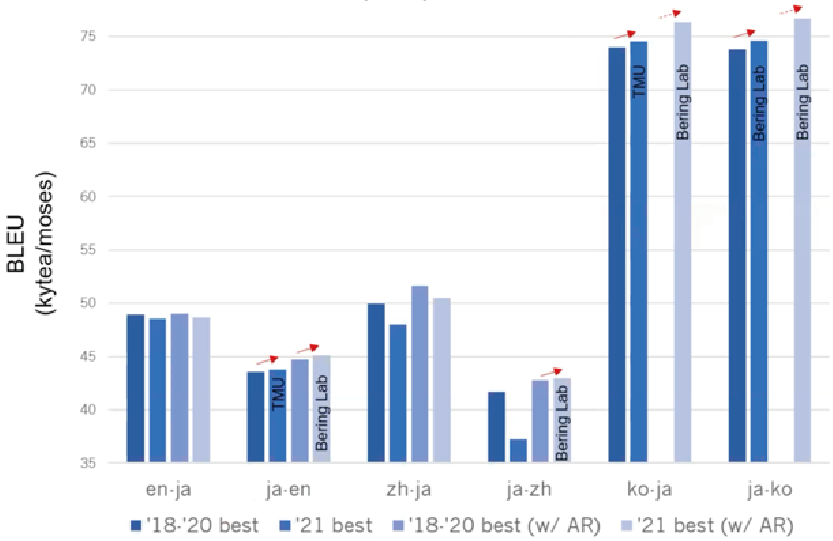
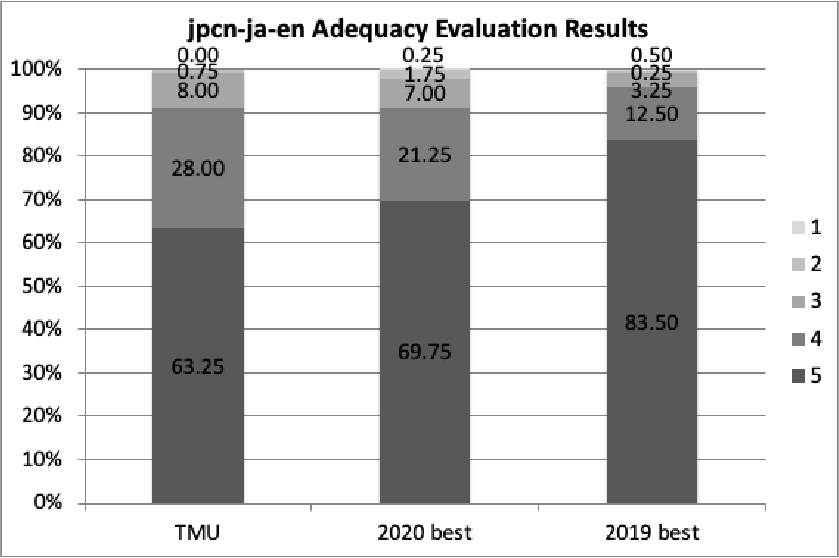
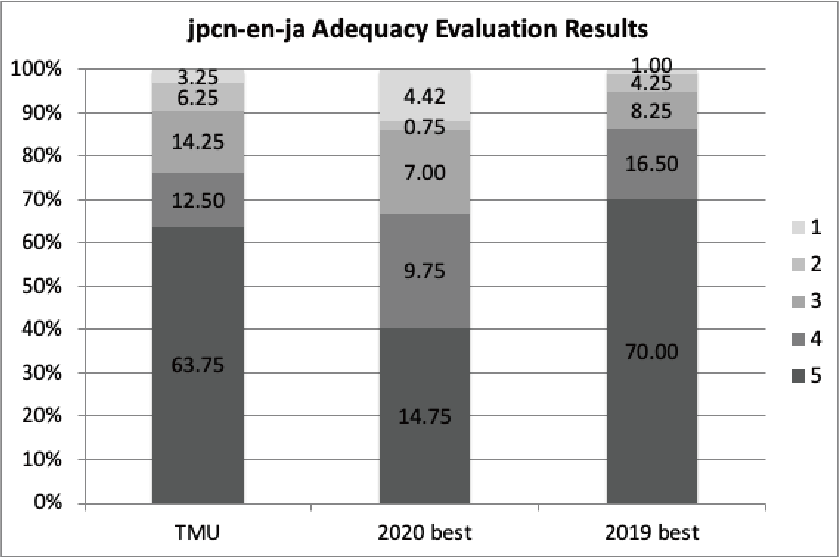
Bering LabはJPCコーパスに加えて、自前で用意した1300万文からなる特許対訳コーパスも合わせて用いており、これのおかげで高いBLEUスコアを達成している。TMUはfine-tuningされた日本語のBART[5]モデルを利用しており、韓日翻訳において最も良いAM-FMスコアを達成した。日英・英日の人手評価結果を見ると、残念ながら過去のWATでのベストなシステムと比べるとやや低い精度という結果であった。しかしながら、BARTという新たなNMTの枠組みを利用しても、過去のシステムに引けを取らない精度であることが示された。
2.2 日英・英日制限翻訳タスク
日英・英日制限翻訳タスクはWAT2021で新たに追加されたタスクである。NMTは訳語統一が不得意であることはよく知られているが、専門用語や固有名詞を特定の用語に常に正しく翻訳することが求められるような文書の種類も多い。この問題に対して、現在の精度を知ることや解決方法を模索するために提案されたのがこのタスクである。
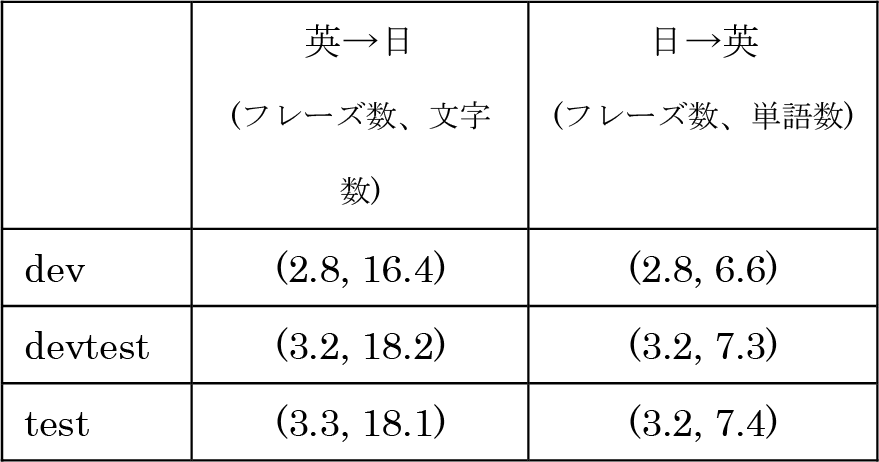
入力文とともに出力文で必ず使わなければならない訳語のリストが与えられるので、システムはこれらの訳語を必ず含むように翻訳を生成しなければならない。なお与えられるのは訳語のリストのみであり、入力文のどの語に対応する訳語なのかは与えられない。今回はASPEC の日英データ(dev/devtest/test)を対象とし、10人のバイリンガルに依頼して専門用語(制限用語)の抽出を行なった。表2に文単位の制限用語の平均数を示す。
自動評価はBLEUスコアと一貫性スコアにより行い、最終的なシステムのランキングはこれらを組み合わせたスコアにより行なった(表3中のfinal)。一貫性スコアは全ての制限用語が出力できた文の割合であり、最終ランキングは全ての制限用語が出力できた文のみで計算したBLEUスコアにより決定した。人手評価はDirect AssessmentおよびContrastive Assessment[6]により行なった。
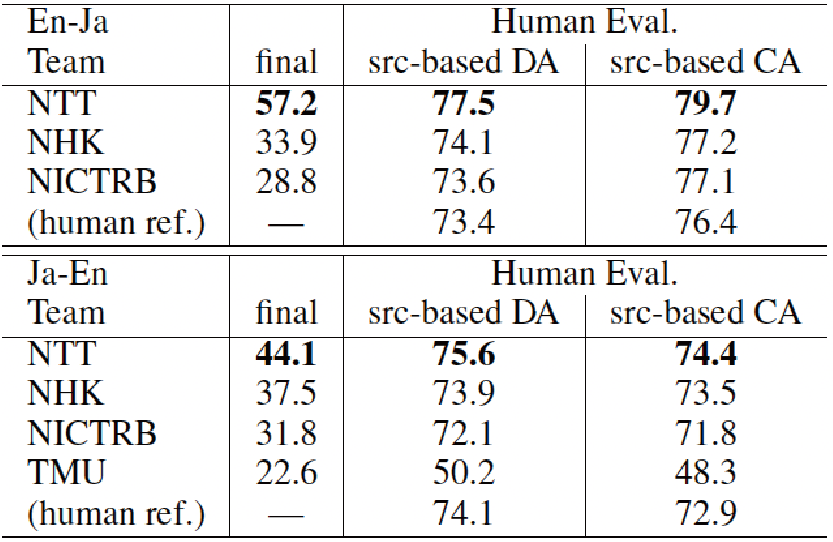
英日翻訳には3システムが参加し、日英翻訳には4システムが参加した。表3に自動評価と人手評価の結果を示す。
全てのシステムが入力文に制限用語を付加して入力し、翻訳時には制限用語を可能な限り出力するように翻訳の探索を行うという方針をとっており、これらの手法は実際に指定された訳語を適切に出力するのに有効であることが示された。
タスクの仕様として訓練データには制限用語が付加されていないため、訓練時にはなんらかの方法で制限用語を準備する必要がある。各システムの違いを見ると、ここでの工夫の仕方が最終的な精度に影響を与えているようである。NHKは固有表現抽出技術により抽出された固有表現と、ベースラインとなるNMTにおいて誤訳となった表現を制限用語として用いるという手法を提案している。一方でNTTはLeCA[7]と呼ばれる手法を用いている。結果を見るとNTTが提案した手法の方が精度良く制限用語を出力し、翻訳精度も高いということが示された。
興味深い点として、元の対訳文の精度(表3中のhuman ref)はそれほど高くないということが示された。今後対訳コーパス自体のクリーニングといったことが必要になる可能性がある。またほとんどのシステムがhuman refよりも高精度を達成しており、現時点でも人間の翻訳に匹敵するような精度であることがわかる。
2.3 日英・英日制限翻訳タスク
Flicker30kの英日翻訳タスクには2チーム、日英翻訳タスクには1チームが参加した。訓練データのサイズが増加したことと、新たな翻訳技術が提案されたことにより、全ての翻訳結果が昨年度の結果よりも良い精度を達成した。英日方向ではテキストのみで翻訳を行なったシステムよりも、画像情報を用いたシステムの方が良い精度であったが、日英方向ではテキスト情報のみを用いたシステムの方が精度が高かった。これは用いたデータセットが英語から日本語へ、画像情報を参照しながら翻訳されたものであることが関係しているものと思われる。また単語の範囲と画像とのソフトアライメントを考慮したシステムを構築したチームが良い精度を達成しており、テキストと画像のグラウンディングが重要であることが示唆される。
Ambiguous MS COCOの英日翻訳タスクには1チームが参加したが、日英翻訳タスクへの参加はなかった。こちらのデータセットにおいても、テキスト情報だけでなく画像情報を適切に用いることで翻訳精度を改善させることができることが示唆された。
3. まとめ
本稿ではWAT2021における特許翻訳タスクと日英制限翻訳タスクおよび日英マルチモーダル翻訳タスクの結果を報告した。アジアの翻訳研究の活性化、データ整備等を目的として2014年に始めたWATは、ドメイン数や言語数の増加、参加者数の増加など一定程度の成果を得ており、WATを通じてアジア地域の機械翻訳研究コミュニティーの連携等が行えると良いと考えている。
NMTの翻訳精度は年々向上しているが、訳抜け、過剰訳、訳語の一貫性、長文の対応など未解決の問題はまだまだ多く残されている。WAT2021で行われた制限翻訳タスクはこのうちの一貫性の問題に注目したものであり、実用的にも重要なタスクとなっている。今後も特定の現象に絞ったようなタスク設計が重要と考えており、引き続きデータの収集や評価指標の定義などを行なっていく予定である。
WATは今後も継続して開催予定であるが、来年度の開催予定は未定である(11月末辺りに決定予定)。またWATでは翻訳評価にかかる費用等のためのスポンサーを募集しているため、興味のある方はご連絡いただければ幸いである。



























































